단일 시계열 모델 분석 - Prophet
시계열 전력 데이터 분석
단일 시계열 모델 분석 - Prophet
Prophet
- Meta Prophet은 시계열 데이터의 예측을 위해 Facebook에서 개발한 오픈소스 라이브러리이다.
- Prophet은 자동화된 이상 탐지 및 계절성 분석을 지원한다.
장점
- Meta에서는 Prophet의 장점을 다음과 같이 소개한다.
- 완전 자동화 : 데이터가 복잡해도 별다른 수작업 없이 합리적인 예측 결과를 얻을 수 있다.
- 강건성 : 이상치, 결측치, 시간 시계열의 극적인 변화에 대해 강건한 성능을 보인다.
- 해석 가능한 매개변수 : 인간이 해석 가능한 매개변수를 사용하여 도메인 지식을 추가함으로써 예측을 개선할 수 있다.
주요 기능
- 추세 변동 : 선형 및 비선형 추세 모델링 지원
- Prophet은 데이터의 장기적인 추세를 모델링할 수 있다.
- 자동으로 최적의 추세 모델을 선택하거나, 사용자가 수동으로 설정할 수 있다.
- 두가지 주요 추세 모델을 지원한다.
- 선형 추세(Linear Trend) : 데이터가 일정한 속도로 증가하거나 감소할 때 사용된다.
- 비선형 추세(Non-linear Trend) : 데이터의 변화 속도가 시간에 따라 변할 때 사용된다.
- 계절성 : 주기적 변동(일, 주, 년 단위)을 모델링
- 기본 계절성
- 연간 계절성
- 주간 계절성
- 휴일 효과 : 공휴일 및 특별 이벤트에 대한 효과를 반영
- 공휴일 리스트를 제공하여 모델에 추가할 수 있다.
- 결측치 처리 : 자동으로 결측치를 처리하고 불규칙한 시계열 데이터를 다룰 수 있음
- 이상치 처리 : 이상치에 강건하다.
모델 사용
사용 데이터
이름 : Panama Electricity Load Forecasting
- column 정보
- nat_demand: National electricity load
- T2M: Temperature at 2 meters
- QV2M: Relative humidity at 2 meters
- TQL: Liquid precipitation
- W2M: Wind speed at 2 meters
- 지역 정보
- toc: Tocumen, Panama city
- san: Santiago city
- dav: David city
- 공휴일 관련 정보
- Holiday_ID: Unique identification number integer
- holiday: Holiday binary indicator (1=holiday, 0=regular day)
- school: School period binary indicator (1=school, 0=vacations)
1
2
3
4
5
import pandas as pd
from sklearn.model_selection import train_test_split
# 데이터 불러오기
data = pd.read_csv("/Users/inderby/Downloads/continuous dataset.csv")
- 데이터 변환
1
2
3
4
5
6
# 데이터를 train set과 test set으로 분할 (80% train, 20% test)
train_data, test_data = train_test_split(data, test_size=0.05,shuffle=False)
# 컬럼 이름 변경
train_data.rename(columns={'datetime': 'ds', 'nat_demand': 'y'}, inplace=True)
test_data.rename(columns={'datetime': 'ds', 'nat_demand': 'y'}, inplace=True)
- 모델 학습 실행
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from prophet import Prophet
model = Prophet()
regressors = ['T2M_toc', 'QV2M_toc', 'TQL_toc', 'W2M_toc',
'T2M_san', 'QV2M_san', 'TQL_san', 'W2M_san',
'T2M_dav', 'QV2M_dav', 'TQL_dav', 'W2M_dav',
'Holiday_ID', 'holiday', 'school']
for regressor in regressors:
model.add_regressor(regressor)
model.fit(train_data)
add_regressor를 통해 모델에 외부 변수를 추가한다.- 이때 훈련 데이터와 예측 데이터에 동일한 변수가 있어야 한다.
- 외부 변수는 수치형 변수여야 한다. 범주형 변수일 경우, one-hot-encoding과 같이 수치형으로 변환을 수행해줘야 한다.
- 데이터의 시간 형식과 간격을 확인하여 일관되게 유지해야 한다.
1
2
3
4
5
6
7
8
# 예측을 위한 미래 데이터프레임 생성 (테스트 데이터와 동일한 기간)
future = test_data[['ds'] + regressors]
# 예측 수행
forecast = model.predict(future)
# 예측 결과 확인
print(len(forecast), len(test_data)) # 744 744
- 예측 결과 비교 및 시각화
- 트렌드 시각화
1
2
3
4
5
6
7
8
9
from prophet.plot import plot_forecast_component, add_changepoints_to_plot
import matplotlib.pyplot as plt # plt를 사용하기 위해 추가
# 예측 결과 시각화 (Matplotlib)
fig1 = model.plot(forecast)
plt.show()
# 컴포넌트 시각화 (Matplotlib)
fig2 = model.plot_components(forecast)
plt.show()
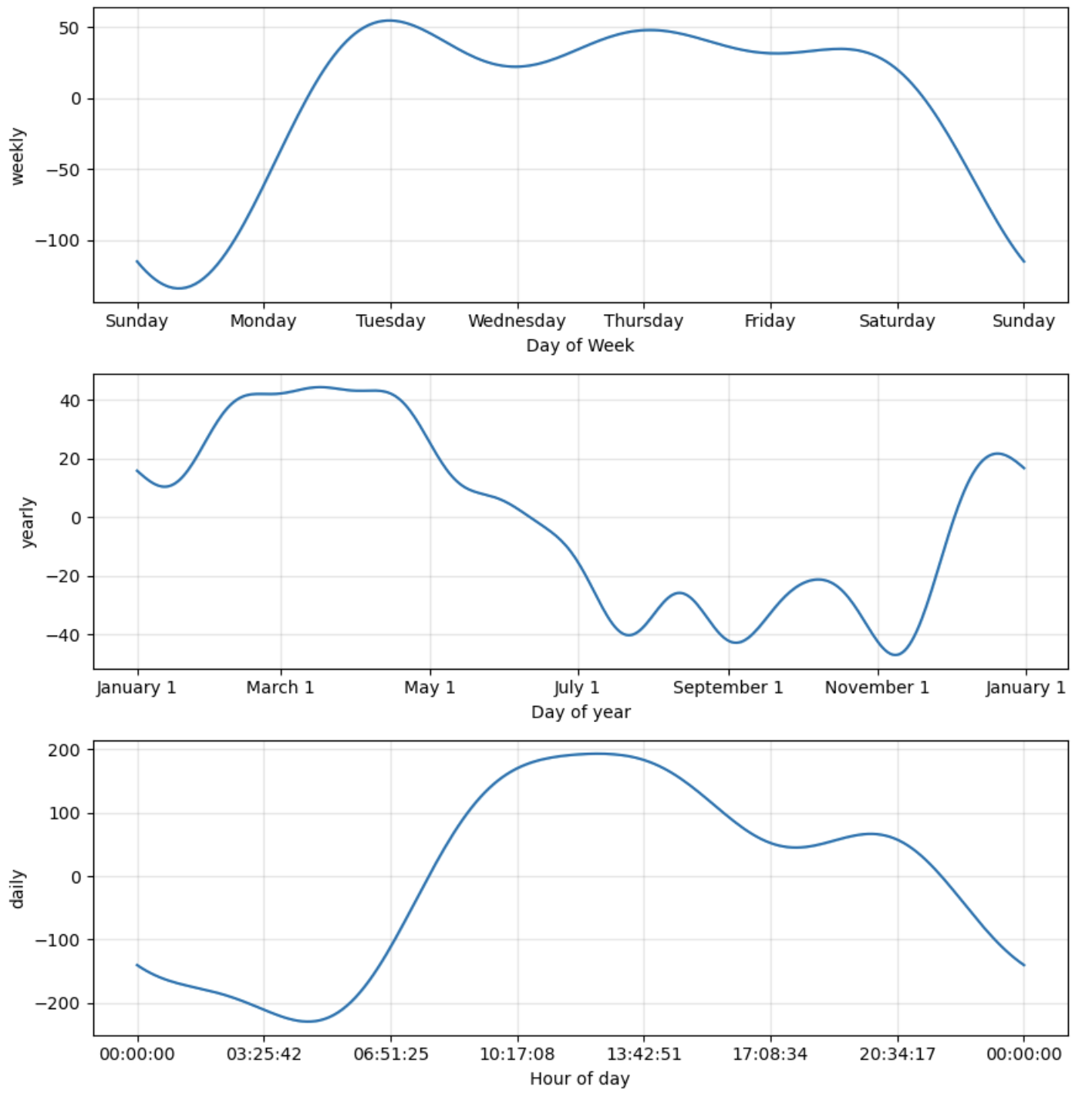
- 예측 데이터 비교 및 시각화
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
# 실제값과 예측값 병합
result = test_data.copy()
result['yhat'] = forecast.set_index('ds').loc[test_data['ds']]['yhat'].values
# 예측 결과 시각화
plt.figure(figsize=(20, 4))
plt.plot(result['ds'], result['y'], label='Actual')
plt.plot(result['ds'], result['yhat'], label='Predicted', linestyle='dashed')
plt.fill_between(forecast['ds'], forecast['yhat_lower'], forecast['yhat_upper'], color='gray', alpha=0.2)
plt.legend()
plt.show()
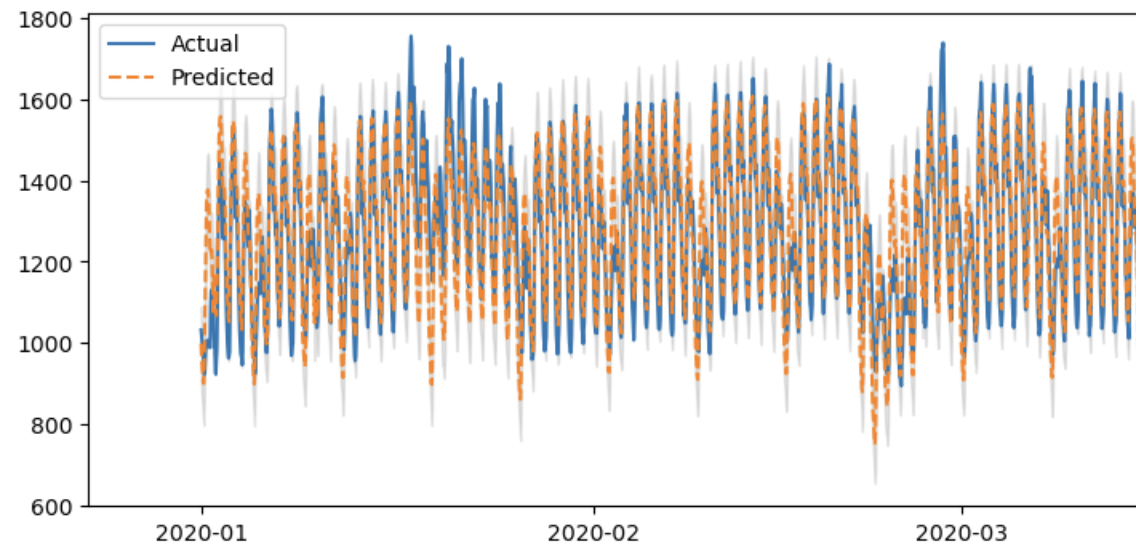
- 성능 평가
- 예측 결과를 실제 테스트 데이터와 비교하여 성능을 검증한다.
1
2
3
4
5
6
7
8
9
from sklearn.metrics import mean_squared_error
# 실제값과 예측값 병합
result = test_data.copy()
result['yhat'] = forecast.set_index('ds').loc[test_data['ds']]['yhat'].values
# 성능 평가 (MSE)
mse = mean_squared_error(result['y'], result['yhat'])
print(f'Mean Squared Error: {mse}')
This post is licensed under CC BY 4.0 by the author.