Operating System.7 Processor Scheduling 2
오퍼레이팅 시스템(운영체제) 공부
Operating System.7 Processor Scheduling 2
Multiple-Processor(MP) System
- Multiple-Processor System은 여러 개의 프로세서를 사용하여 시스템의 성능을 향상시키는 컴퓨터 아키텍처이다.
MP System의 종류
Symmetric Multiprocessing (SMP)
- 모든 프로세서가 동등한 지위를 가지며, 공유 메모리에 대한 접근 권한도 동일하다.
- 각 프로세서는 독립적으로 작업을 수행하지만, 필요에 따라 상호 협력할 수 있다.
- 프로세서 간의 커뮤니케이션과 동기화 오버헤드가 있을 수 있다.
- 대부분의 현대 멀티코어 CPU 시스템이 SMP 아키텍처를 채택하고 있다.
Non-Uniform Memory Access (NUMA)
- 물리적 메모리가 여러 개의 노드로 분할되어 각 프로세서에 독립적으로 할당된다.
- 프로세서는 자신에게 할당된 로컬 메모리에 빠르게 접근할 수 있지만, 원격 노드의 메모리에 접근할 때는 상대적으로 느리다.
- 메모리 접근 시간이 균일하지 않기 때문에 ‘Non-Uniform’이라고 부른다.
- 대규모 시스템에서 확장성을 높이기 위해 사용된다.
Asymmetric Multiprocessing (AMP)
- 마스터-슬레이브 모델로, 한 프로세서가 시스템을 제어하고 다른 프로세서는 특정 태스크를 실행한다.
- 마스터 프로세서는 슬레이브 프로세서에 작업을 할당하고, 전체적인 시스템 조율을 담당한다.
- 프로세서 간의 역할과 권한이 동등하지 않다.
- 실시간 시스템, 임베디드 시스템 등에서 사용된다.
Clustered Multiprocessing
- 여러 대의 독립적인 컴퓨터를 고속의 네트워크로 연결하여 하나의 시스템처럼 동작하게 만든 구성이다.
- 각 노드는 독자적인 운영 체제, 메모리, 프로세서를 가지고 있다.
- 노드 간에는 메시지 패싱 방식으로 통신이 이루어진다.
- 고가용성, 높은 확장성이 요구되는 대규모 병렬 처리 환경에 적합하다.
- 이 외에도 Massively Parallel Processing (MPP), Grid Computing 등 다양한 형태의 Multiple-Processor System이 존재힌다
MP Design Issues
- The actual dispatching of a process
- How to maintain the ready queue
- The assignment of processes to processors
- How to manage processor heterogeneity
MP와 Scheduling의 관계
- 코어 수가 증가함에 따라 개별 코어 레벨에서의 스케줄링 이득이 줄어드는 경향이 있다.
- 이유
- 동기화 오버헤드 증가
- 코어 수가 많아질수록 공유 자원에 대한 경쟁이 심해지고, 동기화를 위한 오버헤드가 증가한다.
- 락(lock), 세마포어(semaphore) 등의 동기화 메커니즘으로 인해 코어 간의 통신 및 조율에 드는 비용이 커진다.
- 캐시 일관성 문제
- 각 코어는 독자적인 캐시를 가지고 있는데, 코어 수가 늘어날수록 캐시 간의 일관성을 유지하기 어려워진다.
- 한 코어에서 공유데이터를 수정하면 다른 코어의 캐시에도 이를 반영해야 하므로, 일관성 프로토콜로 인한 오버헤드가 발생한다.
- 메모리 대역폭 제한
- 여러 코어가 동시에 메모리에 접근하면 메모리 대역폭이 병목 될 수 있다.
- 코어 수에 비해 메모리 대역폭이 충분하지 않으면 코어 간의 경쟁으로 인해 메모리 접근 지연이 발생할 수 있다.
- 부하 불균형
- 워크로드를 코어에 고르게 분배하는 것이 어려워질 수 있다.
- 일부 코어는 바쁜 반면 다른 코어는 유휴 상태일 수 있으며, 이는 전체적인 시스템 활용률을 저하시킨다.
- 확장성의 한계
- 애플리케이션 자체가 높은 병렬성을 내재하고 있지 않으면 코어 수를 늘려도 성능 향상에 한계가 있다.
- 임달의 범칙(Amdahl’s Law)에 따르면 직렬 부분이 존재하는 프로그램은 아무리 코어를 많이 사용해도 속도 향상에 제한이 있다.
- 동기화 오버헤드 증가
- 따라서 코어 수를 무작정 늘리는 것보다는 워크로드의 특성을 파악하고, 적절한 수준의 병렬화를 통해 효율적인 자원 활용을 도모하는 것이 중요하다.
- 또한 운영 체제 및 미들웨어 차원에서 다중 코어 시스템에 최적화된 스케줄링 기법들을 적용함으로써 코어 수 증가에 따른 오버헤드를 최소화하려는 노력이 필요하다.
Single Queue MP Scheduling
- Single-Queue Multiprocessor Scheduling은 다중 프로세서 시스템에서 사용되는 스케줄링 기법 중 하나로, 모든 프로세서가 하나의 공유 큐(shared queue)에서 태스크를 가져와 실행하는 방식이다.
이 스케줄링 기법의 특징과 동작 방식은 다음과 같다:
- 공유 큐(Shared Queue)
- 시스템의 모든 프로세서가 접근 가능한 하나의 글로벌 큐가 존재한다.
- 이 큐에는 실행 가능한 모든 태스크(프로세스 또는 스레드)가 저장된다.
- 큐는 일반적으로 선입선출(FIFO) 방식으로 동작하지만, 우선순위 기반으로 구현될 수도 있다.
- 태스크 할당
- 프로세서들은 공유 큐에서 태스크를 가져와 실행한다.
- 각 프로세서는 독립적으로 큐에 접근하여 가장 앞에 있는 태스크를 선택하고 실행한다.
- 태스크 할당은 프로세서의 상태(유휴/바쁨)에 따라 동적으로 이루어진다.
- 부하 분산(Load Balancing)
- Single-Queue 방식은 자연스럽게 부하 분산 효과를 가져온다.
- 프로세서들이 공유 큐에서 태스크를 가져가므로, 자동적으로 작업량이 프로세서에 고르게 분배된다.
- 한 프로세서가 바쁜 동안 다른 프로세서는 큐에서 새로운 태스크를 가져와 실행할 수 있다.
- 확장성(Scalability)
- Single-Queue 방식은 프로세서 수가 증가해도 비교적 간단하게 확장할 수 있다.
- 새로운 프로세서를 추가할 때 공유 큐에 대한 접근만 가능하도록 하면 되므로, 구현이 용이하다.
- 동기화 오버헤드
- 모든 프로세서가 하나의 공유 큐에 접근하므로, 큐에 대한 동기화가 필요하다.
- 한 번에 하나의 프로세서만 큐에서 태스크를 가져갈 수 있도록 상호배제(Mutual Exclusion)를 구현해야 한다.
- 이로 인해 프로세서 간의 경쟁과 잠금(Lock) 오버헤드가 발생할 수 있다.
- 캐시 친화성(Cache Affinity)
- Single-Queue 방식에서는 태스크와 프로세서 간의 캐시 친화성을 고려하기 어렵다.
- 한 태스크가 서로 다른 프로세서에서 실행될 수 있으므로, 캐시 미스(miss)가 자주 발생할 수 있다.
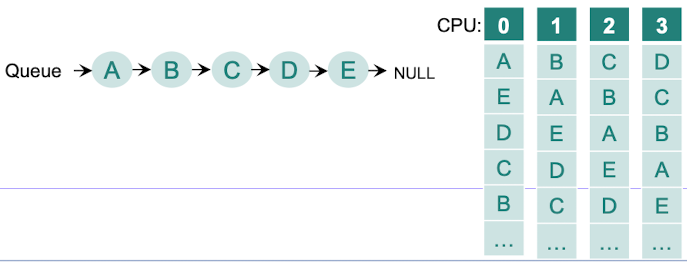
- Single-Queue 방식은 구현이 간단하고 부하 분산 효과가 좋지만, 프로세서 수가 많아질수록 공유 큐에 대한 경쟁으로 인한 오버헤드가 증가할 수 있다.
- 따라서 대규모 시스템에서는 Multi-Queue 등의 다른 스케줄링 기법을 사용하는 것이 더 적합할 수 있다.
- 그럼에도 불구하고 Single-Queue 방식은 간단하고 효과적인 스케줄링 솔루션으로, 중소규모의 다중 프로세서 시스템에서 널리 활용되고 있다.
Processor Affinity(프로세서 선호도)
- 특정 태스크 또는 스레드를 특정 프로세서 코어에 고정하여 실행하는 기법이다.
- 이를 통해 태스크와 프로세서 간의 친화성을 높임으로써 시스템의 성능과 효율성을 향상 시킬 수 있다.
- 캐시 지역성(Cache Locality)
- 태스크를 항상 동일한 프로세서 코어에서 실행하면 캐시 히트율을 높일 수 있다.
- 태스크가 사용하는 데이터와 명령어가 해당 코어의 캐시에 이미 존재할 가능성이 높아진다.
- 캐시 미스가 줄어들어 메모리 접근 시간이 단축ㄷ죄고 성능이 향상된다.
- 장점
- 문맥전환 오버헤드 감소 : 문맥 전환 시 레지스터, 프로그램 카운터 등의 상태를 저장하고 복원하는 비용이 들지만, Processor Affinity를 사용하면 이러한 오버헤드를 최소화할 수 있다.
- 단점
- 부하 불균형 문제 : 일부 코어는 과도하게 사용되는 반면, 다른 코어는 유휴 상태일 수 있습니다.
- 유연성 감소 : 태스크의 실행을 특정 코어로 제한하므로 스케줄링의 유연성이 감소한다.
- 구현 방법
- Processor Affinity는 운영 체제나 시스템 라이브러리에서 제공하는 API를 통해 구현할 수 있다.
- Windows에서는 SetThreadAffinityMask(), Linux에서는 sched_setaffinity()와 같은 함수를 사용한다.(hard affinity)
- 애플리케이션 레벨에서 특정 스레드나 프로세스의 선호도를 설정할 수 있다.
Multi-Queue MP Scheduling
- 프로세서가 자신만의 전용 큐(dedicated queue)를 가지고 태스크를 관리하는 방식이다.
이 스케줄링 기법의 특징과 동작 방식은 다음과 같다:
- 전용 큐(Dedicated Queue)
- 각 프로세서마다 자신의 로컬 큐를 가지고 있다.
- 이 큐는 해당 프로세서에서 실행할 태스크(프로세스 또는 스레드)들을 저장한다.
- 전용 큐는 프로세서 간에 공유되지 않으며, 각 프로세서는 자신의 큐에 대한 독점적인 접근 권한을 가진다.
- 태스크 할당
- 새로운 태스크가 시스템에 도착하면 특정 프로세서의 전용 큐에 할당된다.
- 할당 방법은 라운드 로빈, 무작위 선택, 부하 균등화 등 다양한 정책을 사용할 수 있다.
- 한 번 할당된 태스크는 해당 프로세서의 큐에 머무르며, 다른 프로세서로 이동하지 않는다.
- 로컬 스케줄링
- 각 프로세서는 자신의 전용 큐에 있는 태스크들을 독립적으로 스케줄링한다.
- 프로세서는 자신의 큐에서 태스크를 선택하여 실행하며, 이는 로컬 스케줄링 정책에 따라 결정된다.
- 로컬 스케줄링 정책으로는 우선순위 기반, 시간 할당 등 다양한 알고리즘을 사용할 수 있다.
- 부하 분산
- Multi-Queue 방식에서는 초기 태스크 할당 시 부하 분산을 고려한다.
- 새로운 태스크를 적절한 프로세서의 큐에 할당함으로써 전체 시스템의 부하를 균등하게 분배한다.
- 그러나 런타임에 부하 불균형이 발생할 수 있으며, 이를 해결하기 위해 태스크 마이그레이션(migration)과 같은 기법이 사용될 수 있다.
- 캐시 친화성(Cache Affinity)
- Multi-Queue 방식은 태스크와 프로세서 간의 캐시 친화성을 높일 수 있다.
- 한 태스크가 항상 동일한 프로세서에서 실행되므로 해당 프로세서의 캐시를 효과적으로 활용할 수 있다.
- 이는 캐시 히트율을 높이고 메모리 접근 시간을 단축시켜 성능 향상으로 이어진다.
- 확장성(Scalability)
- 각 프로세서가 독립적인 큐를 가지므로 프로세서 간의 동기화 오버헤드가 적다.
- Multi-Queue 방식은 프로세서 수가 증가해도 비교적 쉽게 확장할 수 있다.
- 그러나 프로세서 수가 매우 많아지면 전체 시스템의 부하 균형을 유지하는 것이 어려워질 수 있다.
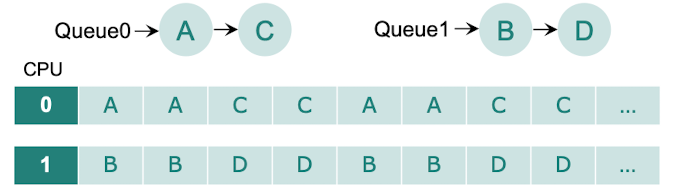
- Multi-Queue 스케줄링은 프로세서 간의 경쟁을 줄이고 캐시 친화성을 높일 수 있는 장점이 있지만, 초기 태스크 할당과 부하 분산 문제에 주의해야 한다.
- 에를 들어 특정 태스크만 많이 발생하여 아래와 같은 상황이 발생할 수 있다.
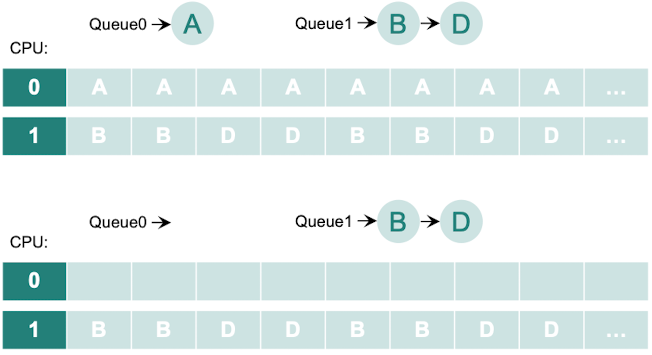
- 에를 들어 특정 태스크만 많이 발생하여 아래와 같은 상황이 발생할 수 있다.
- 이 방식은 대규모 다중 프로세서 시스템, NUMA 아키텍처 등에서 주로 사용되며, 워크로드의 특성과 시스템 구조에 따라 적절히 조정되어 적용됩니다.
Load Balancing
- 다중 프로세서 시스템에서 각 프로세서의 워크로드를 균등하게 분배하여 시스템의 전체 성능을 향상시키는 기법
- 부하 불균형이 발생했을 때 이를 해소하기 위해 태스크 마이그레이션(Task Migration)을 사용할 수 있다.
- Pull Migration
- 부하가 적은 프로세서(언더로드 프로세서)가 능동적으로 태스크를 가져오는 방식이다.
- 언더로드 프로세서는 주기적으로 다른 프로세서의 부하 상태를 모니터링한다.
- 부하가 높은 프로세서는(오버로드 프로세서)를 발견하면 해당 프로세서에 태스크 전송을 요청한다.
- 오버로드 프로세서는 자신의 태스크 중 하나 이상을 선택하여 언더로드 프로세서로 마이그레이션한다.
- Push Migration
- 부하가 높은 프로세서(오버로드 프로세서)가 능동적으로 태스크를 밀어내는 방식이다.
- 오버로드 프로세서는 주기적으로 자신의 부하 상태를 모니터링 한다.
- 부하가 임계값을 초과하면 자신의 태스크 중 하나 이상을 선택하여 다른 프로세서로 마이그레이션 한다.
- 마이그레이션 대상 프로세서는 부하가 적은 프로세서(언더로드 프로세서)를 선택한다.
- Pull Migration
- 각각의 장단점
- Pull Migration은 언더로드 프로세서가 필요한 만큼의 태스크를 가져올 수 있어 효과적인 부하 분산이 가능하지만, 언더로드 프로세서의 수가 많으면 오버헤드가 발생할 수 있다.
- Push Migration은 오버로드 프로세서가 적극적으로 태스크를 분배하므로 빠른 부하 분산이 가능하지만, 마이그레이션 대상 프로세서의 부하 상태를 정확히 파악하기 어려울 수 있다.
Real-Time Scheduling
- Real-Time Scheduling(실시간 스케줄링)은 시간 제약 조건을 가진 태스크들을 다루는 스케줄링 기법으로, 태스크의 데드라인을 준수하는 것이 주요 목표이다.(지연 시간을 최소화 하는 것이 중요하지만, 그것보다는 적절한 시간에 실행, 종료가 되는 것이 중요하다)
실시간 시스템에서는 태스크의 정확성뿐만 아니라 적시성(timeliness)도 중요한 요소이므로, 실시간 스케줄링은 이를 보장하기 위한 특성들을 가지고 있다.
- 시간 제약 조건(Time Constraints)
- 실시간 태스크는 정해진 시간 내에 완료되어야 하는 데드라인(deadline)을 가진니다.
- 데드라인을 지키는 것이 실시간 스케줄링의 가장 중요한 목표이다.
- 시간 제약 조건은 하드(hard) 또는 소프트(soft)로 분류될 수 있다.
- Soft real-time process(연성 실시간) : 덜 중요한 프로세스들보다 우선적으로 실행하는 것만 보장하는 시스템(즉, 반드시는 아니지만 되도록이면 시간을 준수하여 실행되야되는 프로세스)
- Hard real-time process(경성 실시간) : 반드시 마감시간까지 서비스되어야 함.
- 하드 제약 조건은 반드시 지켜져야 하며, 소프트 제약 조건은 가능한 한 지켜져야 한다.
- 예측 가능성(Predictability)
- 실시간 스케줄링은 시스템의 동작을 예측 가능하게 만들어야 한다.
- 각 태스크의 실행 시간, 우선순위, 주기 등이 사전에 알려져 있어야 한다.
- 이를 통해 태스크의 스케줄링 가능성과 데드라인 준수 여부를 미리 분석할 수 있다.
- 예측 가능성은 시스템의 안정성과 신뢰성을 보장하는 데 중요하다.
- 우선순위 기반(Priority-based)
- 실시간 스케줄링은 일반적으로 우선순위에 기반한 스케줄링 알고리즘을 사용한다.
- 각 태스크는 우선순위를 가지며, 우선순위가 높은 태스크가 먼저 실행된다.
- 우선순위는 정적(static)일 수도 있고, 동적(dynamic)일 수도 있다.
- 정적 우선순위는 태스크의 중요도에 따라 미리 할당되며, 동적 우선순위는 시스템의 상태에 따라 실시간으로 변경될 수 있다.
- 선점형(Preemptive)
- 실시간 스케줄링은 대부분 선점형 스케줄링 방식을 사용한다.
- 선점형 스케줄링에서는 우선순위가 높은 태스크가 도착하면 현재 실행 중인 태스크를 중단하고 새로운 태스크를 실행할 수 있다.
- 이를 통해 우선순위가 높은 태스크의 응답 시간을 최소화할 수 있다.
- 선점에 따른 문맥 교환 오버헤드를 최소화하는 것이 중요하다.
- 자원 할당(Resource Allocation)
- 실시간 태스크는 CPU 시간 외에도 다양한 자원(메모리, I/O 장치 등)을 필요로 한다.
- 실시간 스케줄링은 한정된 자원을 태스크 간에 효과적으로 할당해야 한다.
- 자원 할당 시 데드라인, 우선순위, 자원 사용 시간 등을 고려해야 한다.
- 자원 경합과 교착 상태(deadlock)를 방지하기 위한 기법들이 사용된다.
- 고정된 타임 슬롯(Fixed Time Slots)
- 일부 실시간 스케줄링 알고리즘은 고정된 크기의 타임 슬롯을 사용한다.
- 각 타임 슬롯은 특정 태스크 또는 태스크 그룹에 할당되며, 정해진 시간 동안 실행된다.
- 타임 슬롯의 크기와 할당은 시스템의 요구사항과 태스크의 특성에 따라 결정된다.
- 고정된 타임 슬롯은 시스템의 예측 가능성을 높이고 오버헤드를 줄일 수 있다.
- 실시간 스케줄링은 제어 시스템, 로봇, 항공기, 자동차 등 시간 제약 조건이 중요한 다양한 분야에서 사용된다.
- 실시간 스케줄링의 성능은 태스크 집합의 특성, 시스템 구조, 스케줄링 알고리즘의 선택에 따라 달라질 수 있다.
- 대표적인 실시간 스케줄링 알고리즘으로는 Rate Monotonic Scheduling (RMS), Earliest Deadline First (EDF), Deadline Monotonic Scheduling (DMS) 등이 있습니다.
Earliest-Deadline-First(EDF)
- Earliest Deadline First (EDF)는 실시간 시스템에서 사용되는 동적 우선순위 기반의 스케줄링 알고리즘이다.
EDF는 태스크의 절대 데드라인을 기준으로 우선순위를 할당하며, 데드라인이 가장 가까운 태스크를 먼저 실행하는 방식으로 동작한다.
EDF 알고리즘의 주요 특징과 동작 방식
동적 우선순위 할당
- 각 태스크의 우선순위는 절대 데드라인에 따라 동적으로 할당된다.
- 태스크의 데드라인이 가까울수록 높은 우선순위를 받는다.
- 우선순위는 시간이 지남에 따라 변경될 수 있으며, 새로운 태스크가 도착하면 우선순위가 재계산된다.
선점형 스케줄링
- EDF는 선점형 스케줄링 방식을 사용한다.
- 우선순위가 높은 태스크가 도착하면 현재 실행 중인 태스크를 선점하고 새로운 태스크를 실행한다.
- 선점된 태스크는 우선순위가 높은 태스크가 완료된 후에 다시 실행을 재개한다.
최적의 스케줄링 가능 조건
- EDF는 태스크 집합이 특정 조건을 만족할 경우 최적의 스케줄링을 보장한다.
- Liu and Layland의 정리에 따르면, 태스크 집합의 총 CPU 이용률이 1 이하이고 각 태스크의 주기가 데드라인과 같다면 EDF는 모든 태스크의 데드라인을 만족시킬 수 있다.
실행 시간 예측
- EDF 스케줄링의 효과적인 동작을 위해서는 각 태스크의 최악 실행 시간(WCET)을 정확히 예측해야 합니다.
- WCET는 태스크의 실행 경로 중 가장 긴 경로의 실행 시간을 의미합니다.
- WCET를 과소 예측하면 데드라인을 지키지 못할 수 있고, 과대 예측하면 자원 낭비가 발생할 수 있습니다.
과부하 상황 처리
- EDF는 시스템 과부하 상황에서 일부 태스크의 데드라인을 지키지 못할 수 있습니다.
- 과부하 상황을 해결하기 위한 다양한 기법들이 제안되었습니다.
- 예를 들어, 태스크의 주기를 조정하거나, 일부 태스크를 생략하거나, 태스크의 중요도에 따라 우선순위를 조정하는 방법 등이 있습니다.
구현의 간결성
- EDF는 구현이 비교적 간단하고 직관적인 알고리즘입니다.
- 태스크의 데드라인만 추적하면 되므로 구현 복잡도가 낮습니다.
- 그러나 동적 우선순위 할당으로 인한 오버헤드와 문맥 교환 비용을 고려해야 합니다.
- EDF는 이론적으로 최적의 스케줄링 알고리즘으로 알려져 있지만, 실제 시스템에서는 태스크의 특성, 자원 제약, 오버헤드(deadline 갱신을 통한 연산) 등을 고려해야 한다.
- EDF는 주기적인 태스크와 비주기적인 태스크가 혼재된 시스템, 동적으로 변화하는 환경에서 유용하게 사용될 수 있다.
- 그러나 과부하 상황에서는 일부 태스크의 데드라인을 보장하지 못할 수 있으므로 적절한 처리 기법이 필요하다.
Rate Monotonic Scheduling(RMS)
- Rate Monotonic Scheduling (RMS)은 고정 우선순위 기반의 실시간 스케줄링 알고리즘으로, 주기적인 태스크를 스케줄링하는 데 널리 사용된다.
RMS는 각 태스크에 고유한 우선순위를 할당하며, 우선순위는 태스크의 주기에 따라 결정된다.
RMS 알고리즘의 주요 특징과 동작 방식:
- 고정 우선순위 할당
- 각 태스크에는 고유한 우선순위가 할당되며, 이 우선순위는 태스크의 주기에 반비례한다.
- 주기가 짧은 태스크일수록 높은 우선순위를 받는다.
- 우선순위는 태스크의 생성 시점에 결정되며, 실행 중에는 변경되지 않는다.
- 선점형 스케줄링
- RMS는 선점형 스케줄링 방식을 사용합니다.
- 우선순위가 높은 태스크가 도착하면 현재 실행 중인 태스크를 선점하고 새로운 태스크를 실행한다.
- 선점된 태스크는 우선순위가 높은 태스크가 완료된 후에 다시 실행을 재개한다.
- Liu and Layland의 이용률 한계
- RMS의 스케줄링 가능 조건은 Liu and Layland의 이용률 한계로 잘 알려져 있다.
- n개의 태스크로 구성된 시스템에서 RMS가 모든 태스크의 데드라인을 보장하기 위한 충분 조건은 다음과 같다:
- 총 CPU 이용률 U가 U ≤ n(2^(1/n) - 1)을 만족해야 한다.
- 예를 들어, 태스크 수가 무한대로 증가할 때 이용률 한계는 약 69.3%로 수렴한다.

- C : Execution Time
- T : period
- U = C/T : Process Utilization
- 위의 예시에서는 세개의 task의 이용률 합이 조건을 만족하므로 스케줄링이 가능하다
- 주기적인 태스크에 적합
- RMS는 주기적인 태스크를 스케줄링하는 데 적합한 알고리즘입니다.
- 각 태스크는 일정한 주기로 반복적으로 실행되며, 태스크의 주기는 데드라인과 같다고 가정합니다.
- 비주기적인 태스크나 데드라인이 주기와 다른 태스크의 경우 RMS의 성능이 보장되지 않을 수 있습니다.
- 구현의 간결성
- RMS는 구현이 간단하고 오버헤드가 적은 알고리즘입니다.
- 태스크의 우선순위가 고정되어 있으므로 동적인 우선순위 조정이 필요하지 않습니다.
- 런타임에 스케줄링 결정을 내리는 데 드는 비용이 적습니다.
- 확장성 제한
- RMS는 태스크 수가 증가할수록 이용률 한계가 감소하는 특성이 있습니다.
- 따라서 태스크 수가 많은 시스템에서는 RMS의 스케줄링 성능이 저하될 수 있습니다.
- 이를 해결하기 위해 태스크를 그룹화하거나 다른 스케줄링 알고리즘과 결합하는 방법 등이 사용될 수 있습니다.
- RMS는 간단하고 효과적인 실시간 스케줄링 알고리즘으로, 주기적인 태스크를 다루는 시스템에서 널리 사용된다.
- 그러나 RMS는 Liu and Layland의 이용률 한계로 인해 시스템 자원의 활용도가 제한될 수 있으며, 비주기적인 태스크나 복잡한 태스크 집합에는 적합하지 않을 수 있다.
- 따라서 시스템의 특성과 요구사항을 고려하여 적절한 스케줄링 알고리즘을 선택하는 것이 중요하다.
O(1) scheduler
- O(1) 스케줄러는 리눅스 커널 2.6 버전에 도입된 스케줄링 알고리즘으로, 이전의 O(n) 스케줄러를 대체하여 상수 시간에 스케줄링 결정을 내릴 수 있도록 설계되었다.
O(1) 스케줄러는 프로세스의 우선순위와 실행 시간을 기반으로 스케줄링을 수행한다.
- O(1) 스케줄러의 주요 특징과 동작 방식은 다음과 같다
- 상수 시간 복잡도
- O(1) 스케줄러는 스케줄링 결정을 내리는 데 걸리는 시간이 프로세스 수에 상관없이 일정하다.
- 스케줄러의 시간 복잡도가 O(1)이라는 것은 스케줄링 오버헤드가 매우 작음을 의미한다.
- 이는 대규모 시스템에서도 효과적으로 동작할 수 있게 해준다.
- 우선순위 기반 스케줄링
- 각 프로세스에는 정적 우선순위와 동적 우선순위가 할당된다.
- 정적 우선순위는 프로세스 생성 시 결정되며 변경되지 않는다.
- 동적 우선순위는 프로세스의 동작에 따라 실시간으로 조정된다.
- 우선순위가 높은 프로세스가 먼저 실행되며, 우선순위가 같은 경우 라운드 로빈 방식으로 실행된다.
- 실행 시간 추적
- O(1) 스케줄러는 각 프로세스의 실행 시간을 추적한다.
- 프로세스가 CPU를 사용한 시간에 따라 동적 우선순위가 감소한다.
- 실행 시간이 길어질수록 프로세스의 우선순위는 점차 낮아진다.
- 이를 통해 CPU 사용 시간이 긴 프로세스의 독점을 방지하고 공평한 CPU 할당을 보장한다.
- 런큐(Runqueue) 사용
- O(1) 스케줄러는 우선순위에 따라 여러 개의 런큐를 사용한다.
- 각 런큐는 해당 우선순위를 가진 프로세스들의 리스트를 관리한다.
- 스케줄러는 가장 높은 우선순위의 런큐에서 프로세스를 선택하여 실행한다.
- 런큐의 개수는 고정되어 있으므로 스케줄링 결정에 드는 시간이 상수로 제한된다.
- 프로세스 마이그레이션
- O(1) 스케줄러는 프로세스의 우선순위 변경에 따라 프로세스를 다른 런큐로 이동시킨다.
- 프로세스의 동적 우선순위가 변경되면 해당 프로세스는 적절한 런큐로 마이그레이션된다.
- 이를 통해 우선순위 변경에 따른 스케줄링 순서를 빠르게 조정할 수 있다.
- 인터랙티브 프로세스 지원
- O(1) 스케줄러는 인터랙티브 프로세스(사용자와 상호작용하는 프로세스)를 우선적으로 처리한다.
- 인터랙티브 프로세스는 일반 프로세스보다 높은 동적 우선순위를 받는다.
이를 통해 사용자 응답성을 향상시키고 대화형 작업의 성능을 보장한다.
- O(1) 스케줄러는 간단하면서도 효율적인 스케줄링 알고리즘으로, 리눅스 커널에서 널리 사용되었다.
- 상수 시간 복잡도와 우선순위 기반 스케줄링을 통해 대규모 시스템에서도 안정적인 성능을 제공할 수 있다.
- 그러나 O(1) 스케줄러는 프로세스의 상태 변화나 우선순위 조정에 따른 오버헤드가 있을 수 있으며, 이를 개선하기 위해 후속 버전의 리눅스 커널에서는 CFS(Completely Fair Scheduler)와 같은 다른 스케줄링 알고리즘이 도입되었다.
Proportional Share Scheduling
- Proportional Share Scheduling(비례적 공유 스케줄링)은 시스템 자원을 사용자나 그룹 간에 비례적으로 할당하는 스케줄링 기법이다.
- 각 사용자나 그룹은 자원 사용에 대한 일정한 비율을 할당받으며, 이를 기반으로 자원이 공정하게 분배된다.
Proportional Share Scheduling의 대표적인 알고리즘으로는 Weighted Fair Queueing (WFQ)이 있다.
- Proportional Share Scheduling의 주요 개념:
- 자원 비율 할당
- 각 사용자나 그룹에는 자원 사용에 대한 비율(weight)이 할당된다.
- 비율은 상대적인 값으로, 전체 비율의 합은 1 또는 100%이다.
- 예를 들어, 사용자 A에게 30%, 사용자 B에게 70%의 자원 비율을 할당할 수 있다.
- 자원 사용량 추적
- 스케줄러는 각 사용자나 그룹의 자원 사용량을 추적한다.
- 자원 사용량은 실행 시간, CPU 사이클, I/O 대역폭 등 다양한 척도로 측정될 수 있다.
- 사용량 추적을 통해 실제 자원 사용이 할당된 비율에 얼마나 부합하는지 파악할 수 있다.
- 자원 할당 조정
- 스케줄러는 주기적으로 각 사용자나 그룹의 자원 사용량을 비교하여 할당량을 조정다.
- 자원을 과도하게 사용한 사용자는 일시적으로 자원 할당을 줄이고, 자원을 적게 사용한 사용자는 할당을 늘린다.
- 이를 통해 장기적으로 각 사용자나 그룹이 할당된 비율만큼 자원을 사용할 수 있도록 보장한다.
Weighted Fair Queueing(WFQ)
- 가중치 기반 큐잉
- WFQ는 각 사용자나 그룹에 대해 별도의 큐를 유지한다.
- 각 큐에는 해당 사용자나 그룹의 비율(가중치)에 따라 서비스 시간이 할당된다.
- 가중치가 높은 큐일수록 더 빈번하게 서비스된다.
- 가상 시간 개념
- WFQ는 가상 시간(virtual time) 개념을 사용하여 패킷의 전송 순서를 결정한다.
- 각 패킷은 도착 시간과 가중치를 기반으로 가상 종료 시간(virtual finish time)을 할당받는다.
- 가상 종료 시간이 가장 빠른 패킷부터 전송된다.
- 공정한 자원 분배
- WFQ는 가중치에 비례하여 각 큐에 자원을 공정하게 할당한다.
- 큐 간의 자원 경쟁 상황에서도 가중치에 따른 비례적 공유를 보장한다.
- 이를 통해 사용자나 그룹 간의 자원 사용량 불균형을 해소할 수 있다.
- 네트워크 트래픽 관리
- WFQ는 네트워크 트래픽 관리에 널리 사용되는 알고리즘이다.
- 네트워크 대역폭을 사용자나 트래픽 클래스 간에 공정하게 분배할 수 있다.
각 트래픽 클래스에 적절한 가중치를 할당하여 서비스 품질(QoS)을 보장할 수 있다.
- Proportional Share Scheduling과 WFQ는 시스템 자원을 사용자나 그룹 간에 공정하게 분배하는 데 효과적인 방법이다.
- 특히 WFQ는 네트워크 트래픽 관리, 멀티미디어 스트리밍, 가상화 환경 등에서 널리 활용되며, 사용자 간의 공평성과 서비스 품질 보장을 위해 중요한 역할을 한다.
- 다만 WFQ는 패킷 단위의 스케줄링으로 인한 오버헤드가 있을 수 있으며, 가중치 설정에 주의가 필요하다.
This post is licensed under CC BY 4.0 by the author.