Operating System.2 Computer System Overview 2
오퍼레이팅 시스템(운영체제) 공부
Operating System.2 Computer System Overview 2
Computer’s Memory
- 컴퓨터 메모리의 제약 사항
- Capacity(용량)
- Cost(비용)
- Access time(접근시간, 빠르기)
Memory Hierarchy
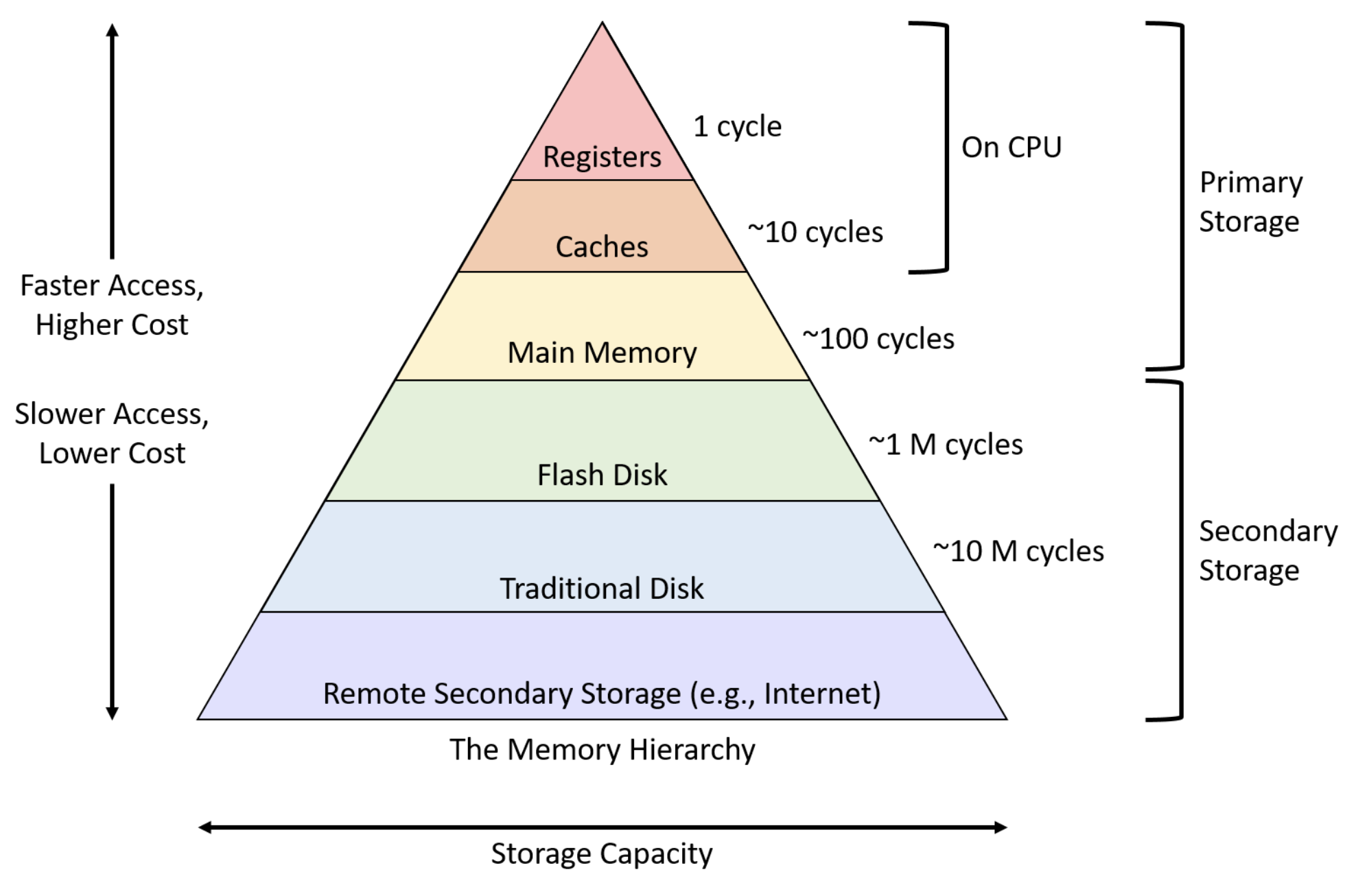
- Register (레지스터):
- CPU 내부에 위치한 가장 빠른 메모리
- 매우 작은 용량 (일반적으로 몇 바이트에서 몇 킬로바이트 정도)
- CPU가 직접 액세스하며, 연산을 위한 데이터와 주소를 일시적으로 저장
- Cache (캐시):
- CPU와 주기억장치 사이에 위치한 고속 메모리
- 자주 사용되는 데이터와 명령어를 저장하여 CPU의 액세스 시간을 단축
- 일반적으로 L1, L2, L3 캐시로 구분되며, 숫자가 커질수록 용량은 크지만 속도는 느려짐
- Main Memory (주기억장치):
- RAM (Random Access Memory)이라고도 함
- 현재 실행 중인 프로그램의 데이터와 명령어를 저장
- 캐시에 비해 용량이 크지만 속도는 상대적으로 느림
- DRAM (Dynamic RAM)과 SRAM (Static RAM)으로 구분
Secondary Storage (보조기억장치):
- 하드 디스크, SSD, USB 드라이브 등과 같은 비휘발성 저장 장치
- 대용량의 데이터를 영구적으로 저장
- 주기억장치에 비해 용량이 매우 크지만 액세스 속도는 가장 느림
- 하위 레벨의 접근 빈도를 줄이는 것이 성능 향상의 포인트이다.
- Locality of Reference(참조의 지역성) : Memory of Hierarchy를 기준으로 자주 사용하는 것을 상위 레벨에 배치 시키는 것
- Temporal Locality(시간적 지역성) : 한번 접근한 Item은 빠른 시일 내에 또 접근할 가능성이 크다.
- Spatial Locality(공간적 지역성) : 한번 접근한 Item 근처에 접근할 가능성이 크다.
Cache
Hit & Miss
캐시 히트(Cache Hit):
- 정의: CPU가 필요로 하는 데이터나 명령어가 캐시 메모리에 존재하는 경우
- 장점: CPU는 캐시에서 직접 데이터를 읽어올 수 있으므로, 주기억장치에 접근하는 것보다 훨씬 빠른 속도로 데이터에 액세스할 수 있다. 이는 시스템의 전반적인 성능을 향상시킨다.
- 히트 시간(Hit Time): 캐시 히트가 발생했을 때, CPU가 캐시에서 데이터를 읽어오는 데 걸리는 시간이다. 이는 일반적으로 클락 사이클 단위로 측정된다.
- 캐시 미스(Cache Miss):
- 정의: CPU가 필요로 하는 데이터나 명령어가 캐시 메모리에 존재하지 않는 경우
- 종류:
- 콜드 미스(Cold Miss) 또는 컴펄서리 미스(Compulsory Miss): 해당 데이터에 대한 최초 접근 시 발생하는 미스로, 캐시에 해당 데이터가 없어서 발생한다.
- 컨플릭트 미스(Conflict Miss): 캐시의 매핑 정책으로 인해 서로 다른 메모리 주소가 캐시의 동일한 위치에 매핑되어 발생하는 미스이다.
- 캐패시티 미스(Capacity Miss): 캐시의 용량이 작아서 모든 필요한 데이터를 저장할 수 없어 발생하는 미스이다.
미스 페널티(Miss Penalty): 캐시 미스가 발생했을 때, 주기억장치에서 데이터를 가져오는 데 걸리는 시간입니다. 이는 캐시 히트 시간보다 훨씬 길다.
캐시 미스가 발생하면 다음과 같은 동작이 수행된다:
- CPU는 캐시에서 원하는 데이터를 찾지 못하고 미스가 발생한다.
- 캐시 컨트롤러는 주기억장치에 데이터를 요청한다.
- 주기억장치에서 데이터를 읽어와 캐시에 해당 데이터를 저장한다..
- 캐시의 교체 알고리즘에 따라 기존 데이터 중 일부를 삭제하고 새로운 데이터로 교체한다.
- CPU는 캐시에 저장된 데이터를 사용한다.
- 캐시의 성능을 향상시키기 위해서는 히트율을 높이고 미스율을 낮추는 것이 중요하다.
- 이를 위해 적절한 캐시 크기, 매핑 방법, 교체 알고리즘 등을 선택해야 한다.
또한, 지역성(Locality) 원리를 고려하여 프로그램을 설계하고 최적화하는 것도 캐시 히트율을 높이는 데 도움이 된다.
- Average Access Time
- T = H * T1 + (1-H)(T1 + T2)
- H : Hit rate, 1-H : Miss rate, T1 : the access time to the upper level, T2 : the access time to the lower level
Cache Memory
- 공간적 지역성 : 미리 근처에 있는 것을 cache에 fetch하자(prefetch) -> Block 단위로 동작하자
- 시간적 지역성 : 자주 사용된 걸 cache에 넣자(기준을 고민해봐야 됨)
Cache Organization
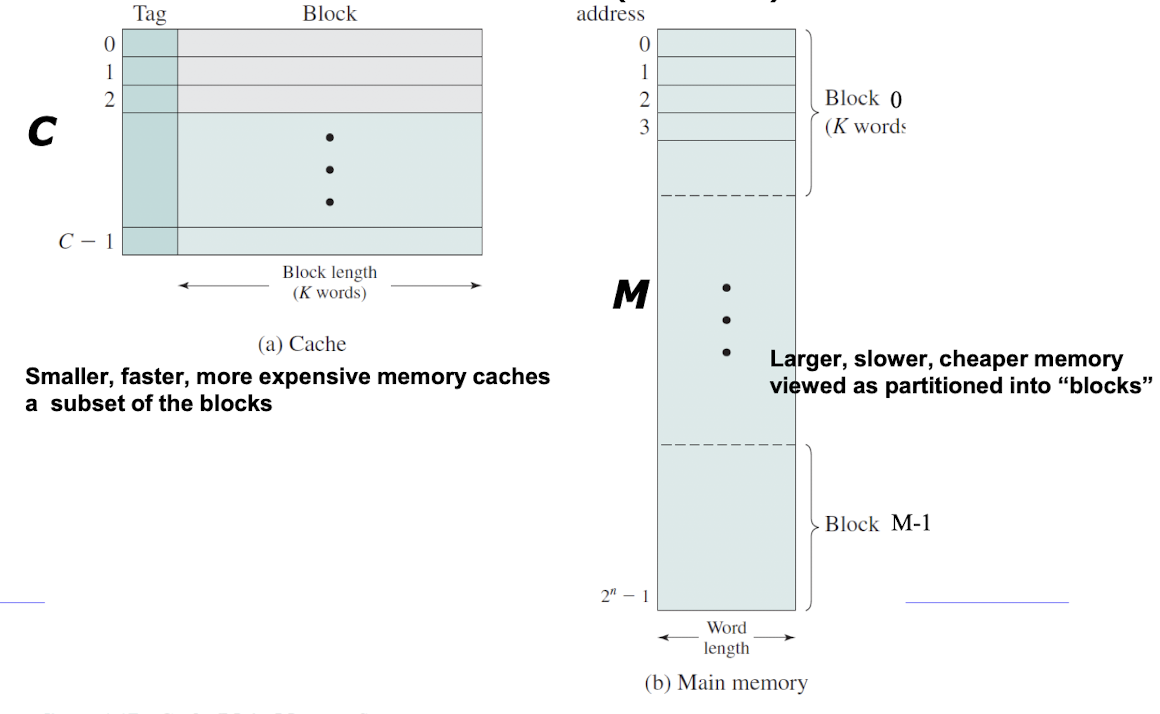
- 메모리는 2^n 형태로 주소들을 구성하므로 fixed-length의 Block M개 로 볼 수 있다(= 2^n/k)(k = block size)
- cache는 C개의 블록으로 구성된다.
Cache Design
- Mapping function : Block이 어디에 위치할지 지정하는 함수
- Direct mapped 방식
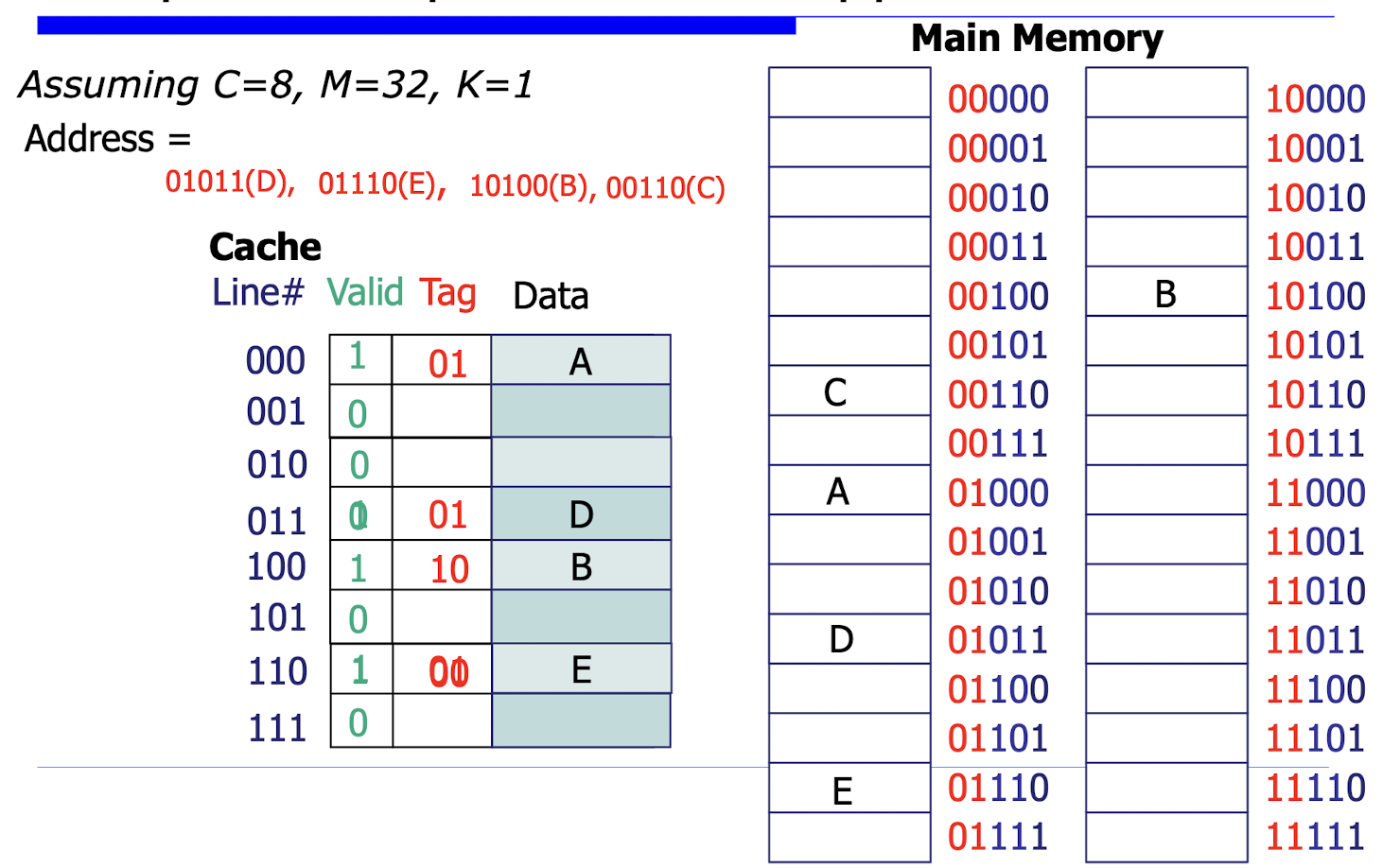
- 가장 간단한 매핑 방식으로, 각 메모리 블록이 캐시의 특정 위치에 직접 매핑된다.
- 주기억장치의 주소를 캐시의 인덱스(Index)와 태그(Tag)로 나누어 사용한다.
- 인덱스는 캐시에서의 위치를 결정하고, 태그는 해당 캐시 라인에 저장된 데이터의 상위 주소 비트를 저장한다.
- 태그는 발견된 값이 찾던 데이터인지 식별해주는 역할이다.
- 장점: 구현이 간단하고, 캐시 액세스 속도가 빠릅니다.
- 단점: 캐시 충돌(Collision)이 자주 발생할 수 있어 미스율이 높아질 수 있습니다.
- 최근에 사용되었던 데이터일지라도 cache memory에서 쫓겨날 수 있다.
- 2-way Set-Associative 방식
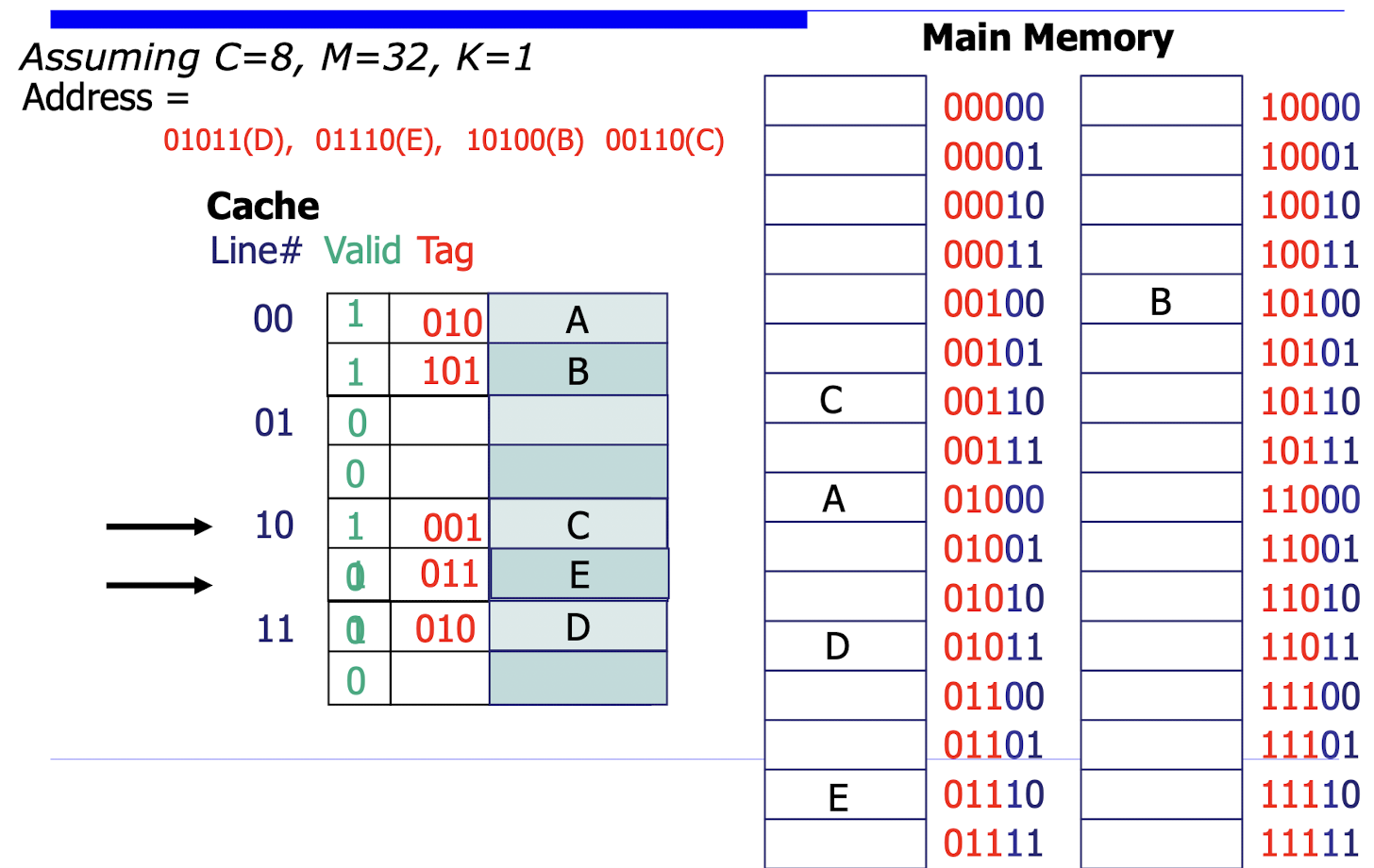
- 캐시를 여러 개의 세트(Set)로 나누고, 각 세트 내에서는 2개의 캐시 라인이 존재하는 방식이다.
- 주기억장치의 주소를 세트 인덱스(Set Index)와 태그(Tag)로 나누어 사용한다.
- 세트 인덱스는 데이터가 저장될 수 있는 세트를 결정하고, 태그는 해당 세트 내에서 데이터를 구분하는 데 사용된다.
- 동일한 세트 인덱스를 가진 메모리 블록들은 같은 세트 내의 2개의 캐시 라인 중 하나에 저장될 수 있다.
- 장점: Direct Mapped 방식에 비해 캐시 충돌 가능성이 낮아져 미스율이 감소한다.
- 단점: 구현이 Direct Mapped 방식보다 복잡하고, 캐시 액세스 시간이 약간 증가할 수 있다.
- 왜냐하면 동일한 공간에 들어갈 수 있는 데이터의 수가 늘어난 것이기 때문에 Look-up비용이 발생함
- 블록의 크기가 크다고 좋은 것은 아님
- 내부 단편화(Internal Fragmentation) 증가
- 캐시 활용도 저하(저장할 수 있는 블록의 수가 줄어들었기 때문)
- 메모리 대역폭 오버헤드 증가(읽거나 쓸 때 한번에 전송해야 되는 데이터량이 증가)
- 메모리 관리 오버헤드 증가(메모리 관리를 위한 메타데이터 증가 및 알고리즘 복잡도 증가)
- cache의 크기가 크다고 좋은 것은 아님.
- 하드웨어 비용 증가
- 액세스 지연 증가
- 전력 소모 증가
- 캐시 일관성 문제
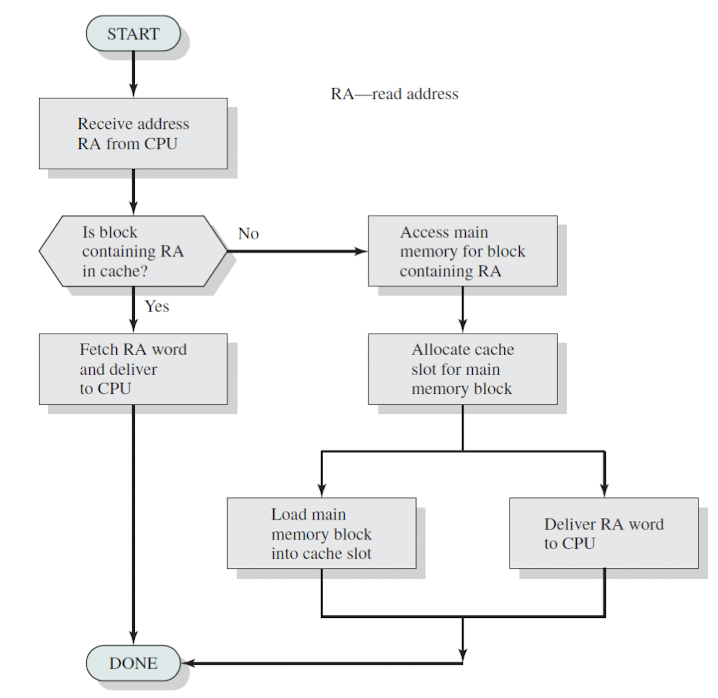
Cache Read Operation
Cache Write Operation
캐시 메모리의 쓰기 작업(Write Operation)과 관련하여 주로 사용되는 정책은 아래와 같다.
Write-Through (직접 쓰기):
- Write-Through 정책에서는 쓰기 작업이 발생할 때 캐시와 주기억장치에 동시에 데이터를 업데이트 한다.
- 쓰기 작업이 완료되려면 주기억장치에 데이터가 안전하게 기록되어야 한다.
- 장점: 캐시와 주기억장치의 데이터 일관성이 항상 유지되며, 구현이 간단하다.
- 단점: 모든 쓰기 작업이 주기억장치로 전파되므로 쓰기 작업의 지연 시간이 길어질 수 있다.
Write-Back (나중에 쓰기):
- Write-Back 정책에서는 쓰기 작업이 발생할 때 일단 캐시에만 데이터를 업데이트하고, 해당 캐시 블록이 교체될 때 주기억장치에 데이터를 기록한다.
- 캐시에서 변경된 데이터는 “더티(Dirty)” 상태로 표시되며, 캐시 블록 교체 시 주기억장치로 기록된다.
- 장점: 쓰기 작업의 지연 시간이 짧아지며, 주기억장치로의 쓰기 트래픽을 줄일 수 있다.
- 단점: 캐시와 주기억장치의 데이터 불일치가 발생할 수 있으며, 구현이 복잡하다.
Write-Allocate (쓰기 할당):
- Write-Allocate 정책은 쓰기 미스(Write Miss)가 발생했을 때 주기억장치에서 해당 블록을 캐시로 가져오는 방식이다.
- 쓰기 작업 시 캐시에 해당 블록이 없으면, 주기억장치에서 블록을 읽어와 캐시에 할당한 후 쓰기 작업을 수행한다.
- Write-Allocate는 Write-Through와 Write-Back 정책 모두에서 사용될 수 있다.
- 장점: 이후의 쓰기 작업에서 캐시 히트율을 높일 수 있다.
- 단점: 쓰기 미스 시 주기억장치에서 블록을 읽어오는 오버헤드가 발생한다.
Write-Back + Write-Allocate:
- Write-Back과 Write-Allocate 정책을 함께 사용하는 방식이다.
- 쓰기 미스가 발생하면 Write-Allocate 정책에 따라 주기억장치에서 블록을 캐시로 온다.
- 쓰기 작업은 Write-Back 정책에 따라 일단 캐시에만 수행되고, 해당 블록이 교체될 때 주기억장치에 기록된다.
- 장점: 쓰기 작업의 지연 시간이 짧고, 이후의 쓰기 작업에서 캐시 히트율을 높일 수 있다.
단점: 구현이 복잡하며, 쓰기 미스 시 주기억장치에서 블록을 읽어오는 오버헤드가 발생한다.
- 각 정책은 시스템의 특성, 워크로드의 쓰기 패턴, 성능 요구 사항 등에 따라 선택된다.
- Write-Through는 구현이 간단하고 데이터 일관성을 유지할 수 있지만, 쓰기 지연 시간이 길 수 있다.
- Write-Back은 쓰기 지연 시간을 줄일 수 있지만, 데이터 불일치 문제를 고려해야 한다.
- Write-Allocate는 쓰기 미스 시 캐시 활용도를 높일 수 있지만, 추가적인 오버헤드가 발생한다.
I/O Controller
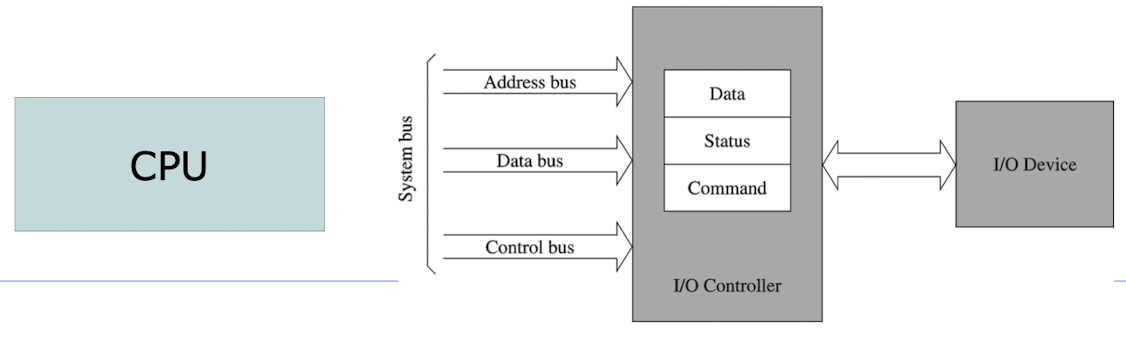
- 컴퓨터와 키보드, 마우스, 프린터 및 네트워크 어댑터 등 입/출력 장치 간의 데이터 전송 관리를 담당한다.
- 물리적 장치와 이를 사용하는 소프트웨어 간에 추상화 계층을 제공하여 효율적이고, 표준화된 통신을 허용한다.
- Data, Status, Command 레지스터를 갖고 있다.
I/O Address Space
- port-mapped I/O : 메모리 Address Space와 별도로 분리된 space를 가지는 방식.
- 추가적인 I/O Instruction으로 값을 읽고, 씀
- 단점 : 추가적인 Instruction을 가져야 함
- Memory-mapped I/O : 메모리 Address Space와 같은 메모리 상의 공간을 사용하는 방식
- 단점 : 실제 메모리 공간을 사용할 수 없는 경우 발생
Programmed I/O(Polling I/O)
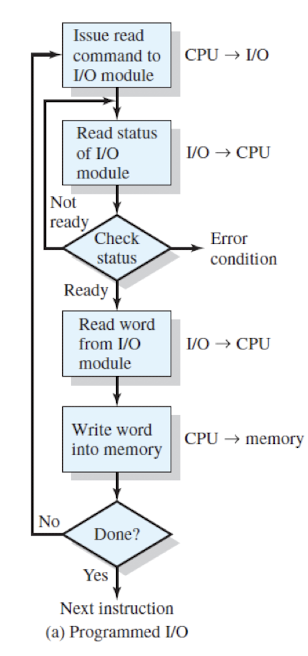
- 반복적 I/O model의 상태를 체크하면서 busy wait한다.
- 빠른 디바이스에는 합리적일 수 있으나, 느린 디바이스에는 비합리적이다.
Interrupt-Driven I/O
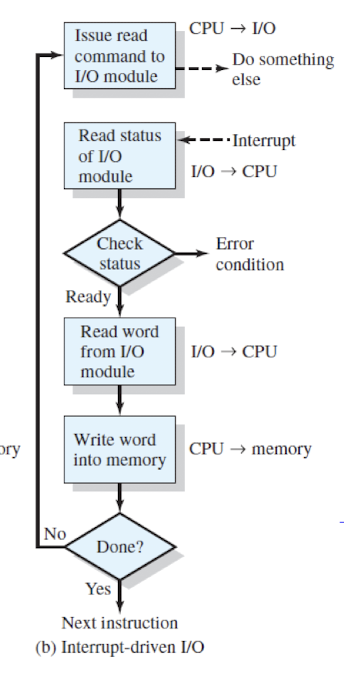
- CPU가 Command를 I/O Controller에게 보내고 바로 다른 작업을 수행하는 방식.
- I/O Controller라는 작업이 끝나면 Interrupt를 보냄
- 단점 : large-data의 이동에서 Interrupt가 계속 발생하면 mode switch 비용이 발생할 수 있다.
DMA(Direct Memory Access)
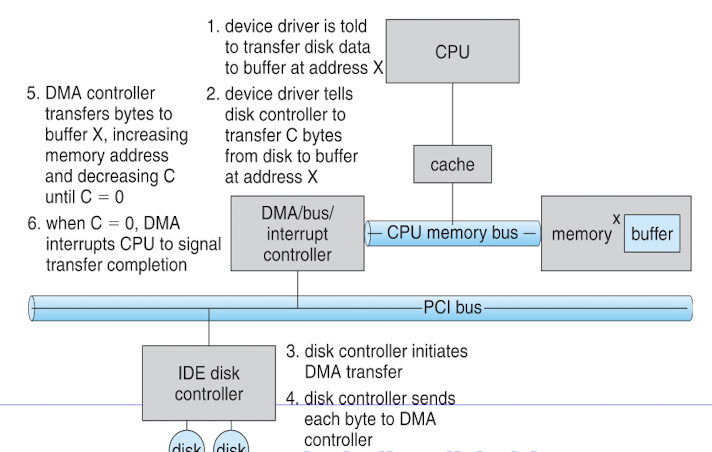
- I/O Controller가 시스템 메모리에 직접 접근하여 CPU를 우회하고, 데이터 전송의 오버헤드를 줄인다.
- DMA Controller를 이용해 I/O Controller가 시스템 메모리에 접근한다.
- 단점 :
- 추가적인 하드웨어(DMA 컨트롤러)가 필요하다.
- 메모리와 입출력 장치 간의 버스 대역폭을 공유하므로, 다른 장치와의 버스 경합이 발생할 수 있다.
- DMA 전송 중에는 CPU가 해당 메모리 영역에 접근할 수 없으므로, 데이터 일관성 문제가 발생할 수 있다.
대칭적 멀티프로세서와 비대칭적 멀티프로세서
대칭적 멀티프로세서(SMP):
- 모든 프로세서가 동등한 역할과 책임을 가진다.
- 모든 프로세서는 공유 메모리에 균등하게 접근할 수 있다.
- 모든 프로세서는 동일한 명령어 세트를 실행할 수 있다.
- 운영 체제는 프로세서 간의 부하 분산을 자동으로 처리한다.
- 프로세서 간의 통신은 공유 메모리를 통해 이루어진다.
- 확장성이 우수하며, 프로세서를 추가하여 성능을 향상시킬 수 있다.
- 프로세서 간의 동기화와 조율이 필요하므로, 오버헤드가 발생할 수 있다.
- 대부분의 현대 멀티코어 시스템은 SMP 아키텍처를 기반으로 한다.
비대칭적 멀티프로세서(AMP):
- 각 프로세서가 특정 작업이나 기능을 전담한다.
- 프로세서 간에 계층적 구조가 존재할 수 있다.
- 주 프로세서(Master Processor)가 시스템을 제어하고, 다른 프로세서에 작업을 할당한다.
- 각 프로세서는 독립적인 메모리 공간을 가질 수 있다.
- 프로세서 간의 통신은 메시지 전달 방식을 사용할 수 있다.
- 특정 작업에 최적화된 프로세서를 사용하여 성능을 향상시킬 수 있다.
- 프로세서 간의 부하 분산이 수동으로 이루어져야 할 수 있다.
- 시스템 설계와 프로그래밍이 복잡해질 수 있다.
- 과거의 일부 시스템에서 사용되었던 방식이다.
현대 컴퓨터 시스템에서는 대부분 SMP 아키텍처를 사용하며, 멀티코어 프로세서가 일반적이다.
Advanced PIC(APIC)
- Local APIC (LAPIC):
- 각 프로세서 코어에 내장된 APIC 유닛이다.
- 프로세서 내부의 인터럽트를 처리하고 관리한다.
- 타이머, 성능 모니터링 카운터, 온도 센서 등의 로컬 인터럽트 소스를 처리한다.
- 인터럽트 우선순위 결정, 인터럽트 마스킹, 인터럽트 벡터 생성 등의 기능을 수행한다.
- 프로세서 간 인터럽트(IPI, Inter-Processor Interrupt)를 전송하고 수신한다.
I/O APIC:
- 시스템의 입출력 장치와 연결된 APIC 유닛이다.
- 외부 인터럽트 컨트롤러의 역할을 수행한다.
- 시스템 버스를 통해 들어오는 외부 인터럽트를 수신하고 관리한다.
- 인터럽트 리다이렉션 테이블(Interrupt Redirection Table)을 통해 인터럽트를 적절한 프로세서의 Local APIC로 전달한다.
- 번외 : 이기종 아키텍처(Heterogeneous Architecture)는 서로 다른 유형의 프로세싱 유닛을 단일 시스템에 통합하는 컴퓨터 아키텍처를 말한다.
- ex : CPU+GPU, CPU+FPGA, CPU+DSP
This post is licensed under CC BY 4.0 by the author.