Operating System.12 Memory management
오퍼레이팅 시스템(운영체제) 공부
Operating System.12 Memory management
Memory Model
Sequential Consistency(순차적 일관성)
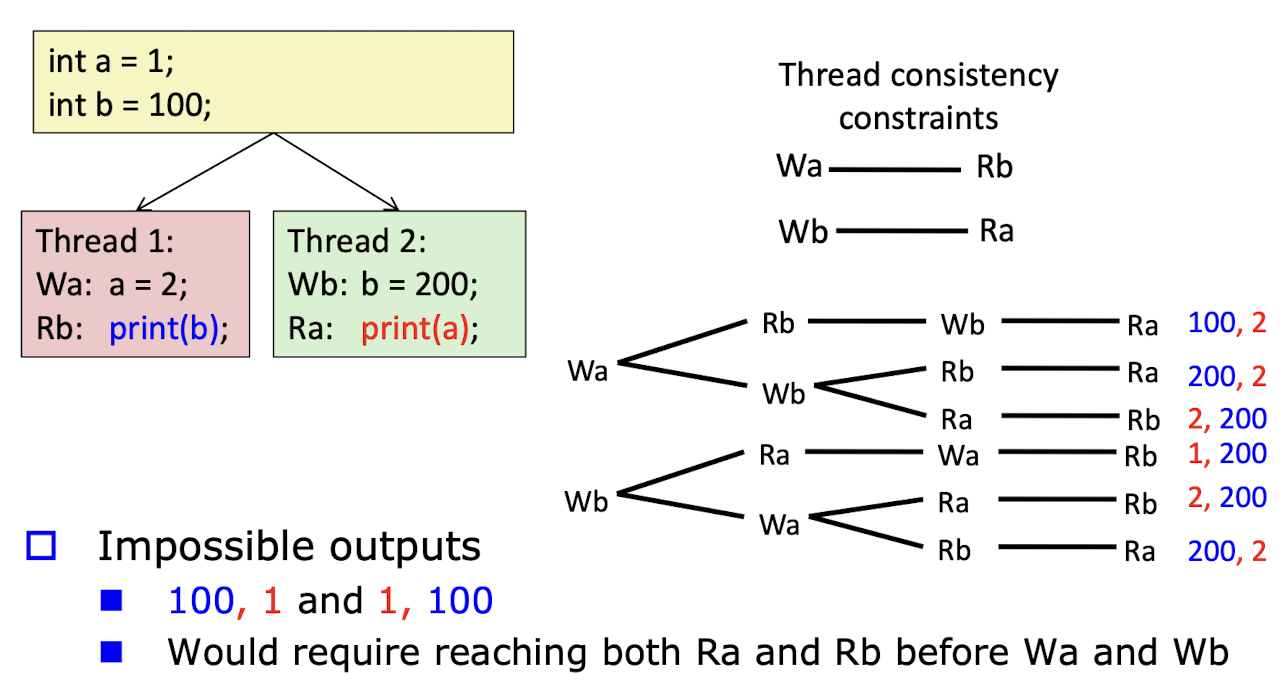
- re-ordering을 고려하지 않은 모델
- 이 모델에서는 모든 프로세서가 메모리 작업을 동일한 순서로 보게 된다
- 최적화, 성능 향상을 하지 못한다.
- 위의 이미지와 같이 코드 실행 순서를 변경할 수 없기에 [100, 1] 또는 [1, 100]은 나올 수 없다.
Relaxed(or Weak) Consistency
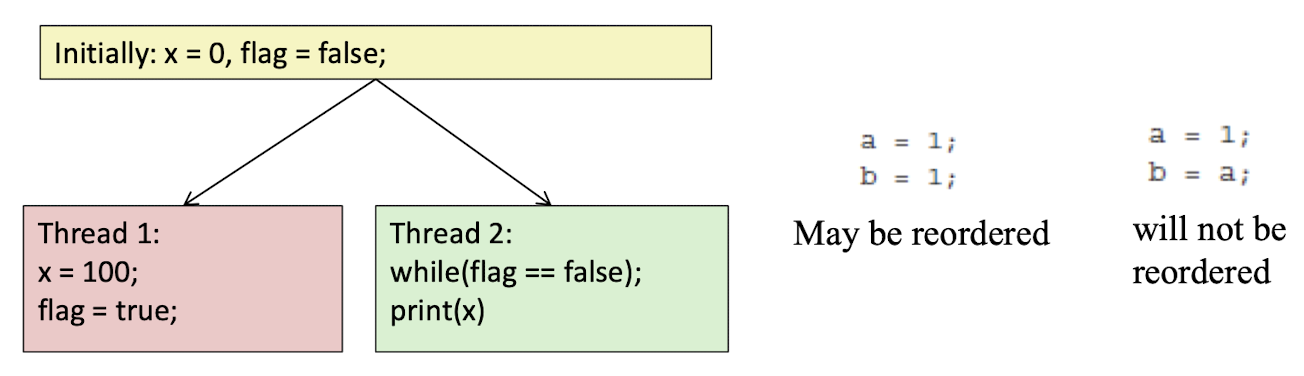
- re-ordering이 되는 모델
- 각 프로세서는 자신의 메모리 작업을 프로그램 순서대로 수행하지만, 다른 프로세서의 메모리 작업 순서와는 다를 수 있다.
Memory Barrier
- 멀티 프로세서 시스템에서 메모리 작업의 순서를 제한하고 동기화하기 위해 사용되는 기술이다.
- 메모리 배리어는 컴파일러와 프로세서에게 메모리 작업의 순서를 재배열하거나 최적화 하지 않도록 지시하는 역할을 한다.
- 사용 목적
- 메모리 작업 순서 보장
- 메모리 가시성 보장
- 최적화 제한
- 메모리 배리어 유형
- Load Barrier(읽기 배리어)
- Load Barrier는 배리어 이전의 메모리 읽기 작업이 배리어 이후의 메모리 읽기 작업보다 먼저 수행되도록 보장한다.
- Store Barrier(쓰기 배리어)
- Store Barrier는 배리어 이전의 메모리 쓰기 작업이 배리어 이후의 메모리 쓰기 작업보다 먼저 수행되도록 보장한다.
- Full Barrier(전체 베리어)
- Load Barrier와 Store Barrier의 기능을 모두 포함한다.
- 배리어 이전의 모든 메모리 작업이 배리어 이후의 모든 메모리 작업보다 먼저 수행되도록 보장한다.
- Load Barrier(읽기 배리어)
Memory Management
- Main memory는 user 영역과 OS 영역으로 나뉨
- Memory를 관리할 때 요구 사항 5가지
- relocation(재배치) : 실행되는 process의 수는 미리 알 수 없기 때문에 고려해야 함(runtime에 해결 필요)
- Protection : 다른 process에 의해 방해 받지 않는 것(runtime에 해결 필요)
- Sharing : 같은 코드는 공유하는 것
- logical organization(논리적 구성) : sharing, protection을 module 별로 진행하는 것이 효율적임
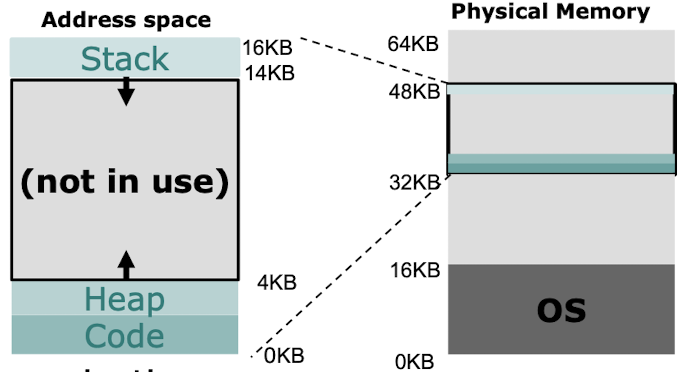
- physical organization : 각기 다른 속성을 가진 다양한 유형 및 수준의 계층으로 구성
Types of Addresses
- Symbol Address : source code에서 사용하는 naming(function, 변수명)
- Logical Address(상대 주소) : offset
- Physical Address(물리 주소) : 실제 메모리의 주소(Logical Address에서 MMU에 의해 변환됨)
Dynamic Address Translation(동적 주소 변환)
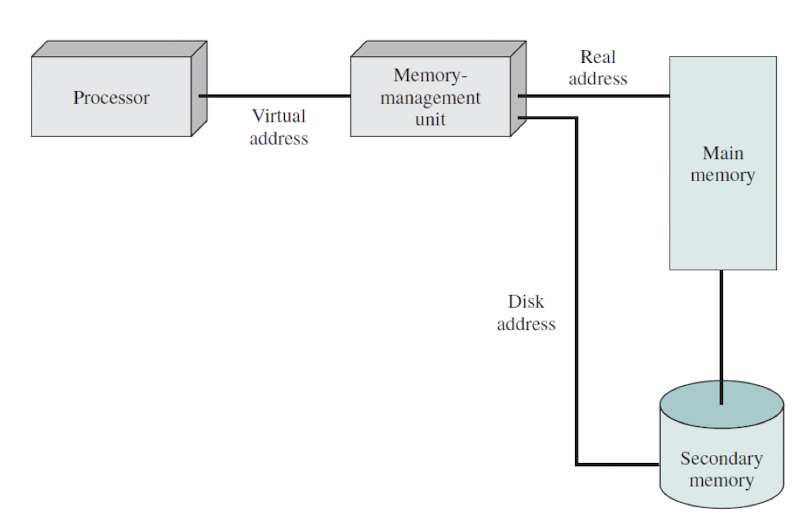
- run-time에 logical(virtual) address를 physical address로 변환
Memory Allocation
- Contigious allocation(연속 할당)
- Fixed partitioning
- equal size
- unequal size
- Dynamic partitioning
- Buddy System
- Fixed partitioning
- Non-Contigious allocation(불연속 할당)
- Paging
- Segmentation
Fixed Partitioning(고정 분할 방식)
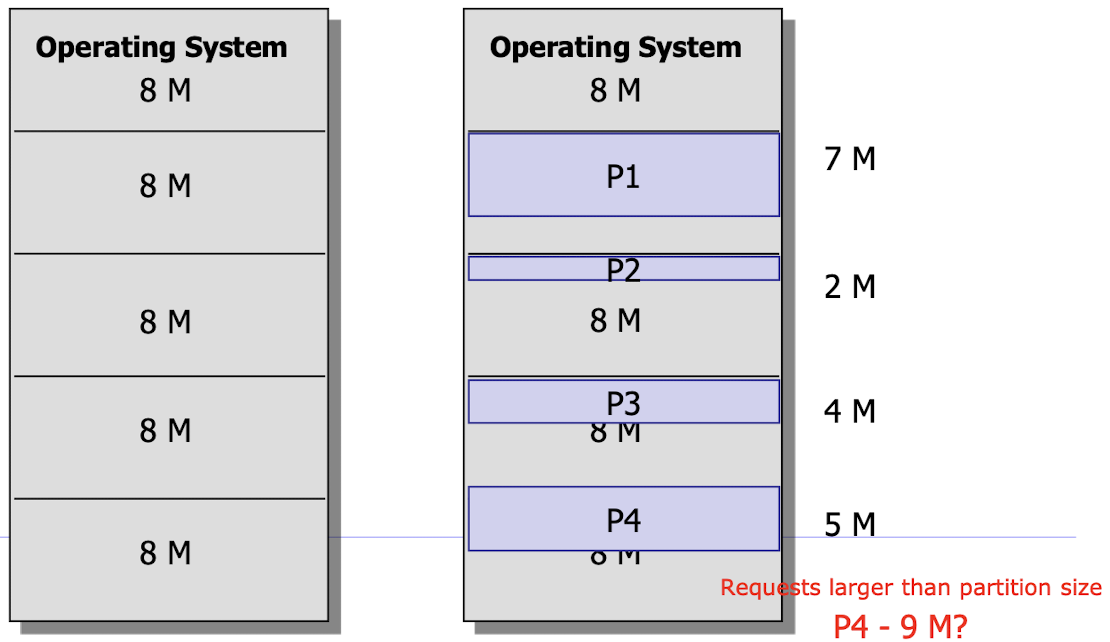
- equal size partitioning : 고정 size의 partition을 미리 쳐놓는 방식
- 단점 : 메모리에 올라갈 수 있는 process의 수가 정해져 있다. 즉, Internal fragmentation(내부 단편화)가 발생한다
- Internal Fragmentation : 할당된 메모리 공간 내에서 미사용 영역이 발생하는 현상
- 단점 : 메모리에 올라갈 수 있는 process의 수가 정해져 있다. 즉, Internal fragmentation(내부 단편화)가 발생한다
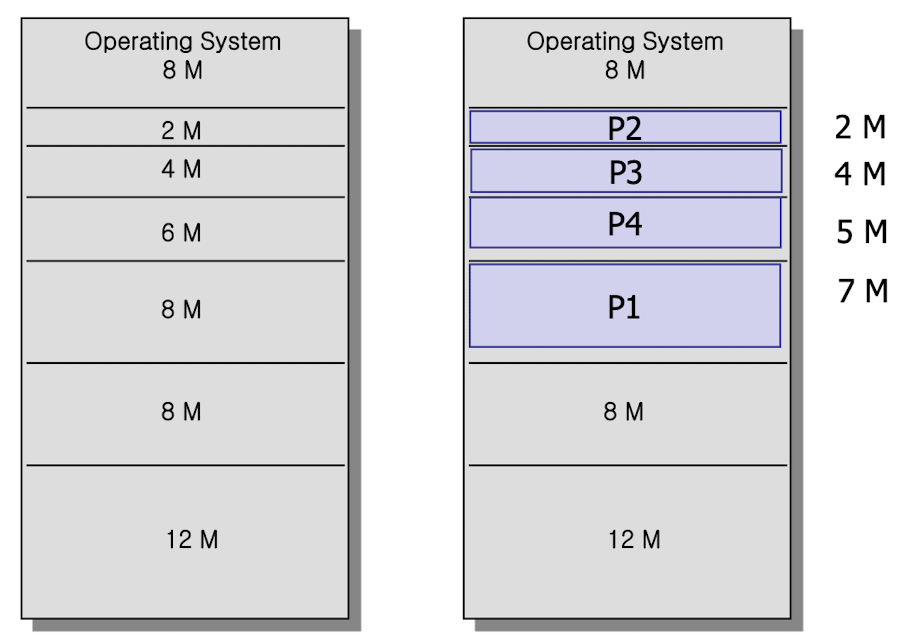
- unequal size partition(비균등 고정 분할)
- internal fragmentation을 어느 정도 minimize할 수 있지만 근본적인 문제는 해결하지 못했다.
Dynamic Partitioning(동적 분할)
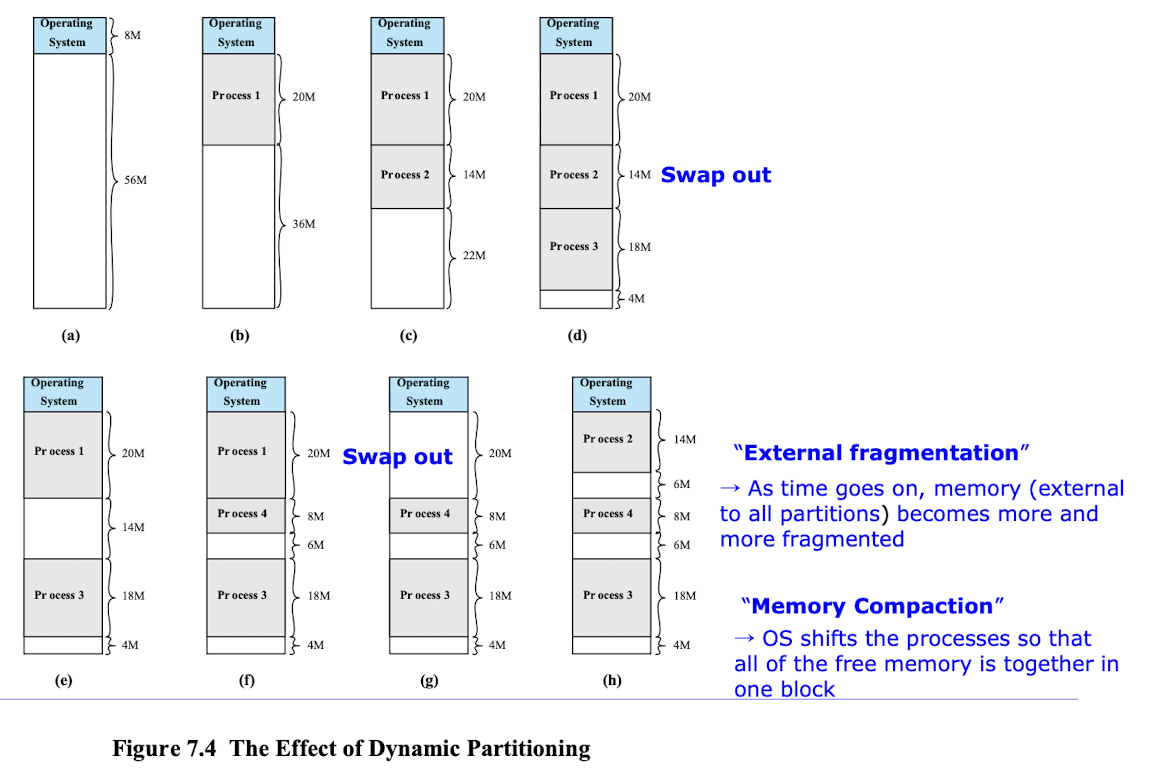
- process가 요구한 만큼만 runtime에 partitioning
- 시간이 지나면서 Process와 Process 사이의 hole이 많아지고, 작아지게 된다.
- 즉, external fragmentation 발생 -> 이러한 hole을 없애기 위한 압축 과정이 필요(OS의 CPU overhead 발생)
- 장점 : Internal fragmentation이 없다. 메모리 사용률이 높다.
- 단점 : 외부 단편화가 발생하여 memory compaction이 발생한다.
Placement Algorithm
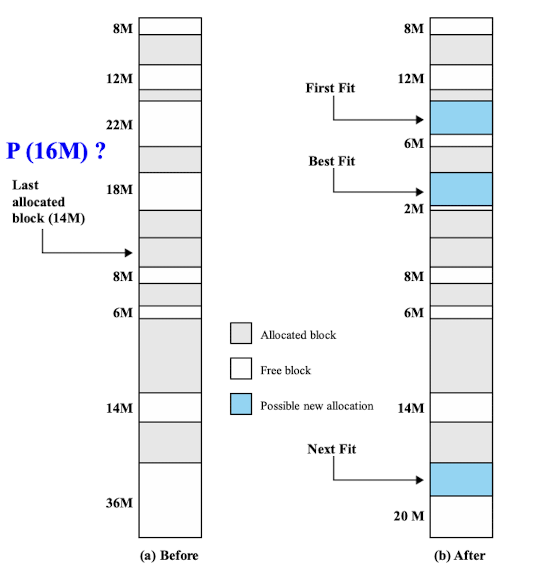
- First-fit : 메모리 블록 리스트를 처음부터 검색하여 프로세스의 메모리 요구량을 수용할 수 있는 첫 번째 블록을 선택한다.
- 장점: 간단하고 구현이 쉬우며, 메모리 블록 검색 시간이 비교적 짧다.
- 단점: 메모리 블록의 크기와 프로세스의 요구량 간의 차이로 인해 내부 단편화가 발생할 수 있다.
- Next-fit : 이전에 할당된 블록의 위치부터 검색을 시작하여 프로세스의 메모리 요구량을 수용할 수 있는 첫 번째 블록을 선택한다.
- 장점: First-fit보다 검색 시간이 빠를 수 있다. 메모리 블록의 사용 빈도를 고르게 분산시킬 수 있다.
- 단점: 여전히 내부 단편화 문제가 발생할 수 있다.
- Best-fit : 메모리 블록 리스트에서 프로세스의 메모리 요구량과 가장 근접한 크기의 블록을 선택한다.
- 장점: 내부 단편화를 최소화할 수 있습니다. 메모리 공간을 효율적으로 사용할 수 있다.
- 단점: 메모리 블록 리스트를 전체적으로 검색해야 하므로 검색 시간이 길어질 수 있다. 작은 크기의 블록들이 많이 생성될 수 있다.
Buddy System(hybrid approach)
메모리 블록의 크기:
- 메모리는 2의 거듭제곱 크기로 분할됩니다. (예: 4KB, 8KB, 16KB, 32KB 등)
- 각 블록의 크기는 이전 블록 크기의 2배입니다.
- 최소 블록 크기부터 최대 블록 크기까지 다양한 크기의 블록들이 존재합니다.
Buddy 블록:
- 인접한 두 개의 동일한 크기의 블록을 Buddy 블록이라고 합니다.
- Buddy 블록은 필요에 따라 합쳐질 수 있으며, 합쳐진 블록은 더 큰 크기의 블록이 됩니다.
- 반대로 큰 블록이 분할될 때, 분할된 블록들은 Buddy 블록이 됩니다.
메모리 할당:
- 프로세스의 메모리 요구량에 맞는 가장 작은 크기의 블록을 찾습니다.
- 요구량보다 큰 블록이 있다면, 해당 블록을 반으로 분할하여 적절한 크기의 블록을 생성합니다.
- 생성된 블록 중 하나를 프로세스에 할당하고, 나머지 블록은 가용 블록 리스트에 추가합니다.
메모리 해제:
- 프로세스가 종료되면 할당된 메모리 블록을 해제합니다.
- 해제된 블록은 인접한 Buddy 블록과 합쳐질 수 있는지 확인합니다.
- 합쳐질 수 있는 Buddy 블록이 있다면, 두 블록을 합쳐서 더 큰 크기의 블록을 생성합니다.
- 합쳐진 블록은 다시 가용 블록 리스트에 추가됩니다.
- 장점 :
- 빠른 메모리 할당과 해제가 가능함.
- 외부 단편화 문제를 해결할 수 있다.
- 메모리 블록의 크기가 2의 거듭제곱이므로, 블록 크기와 주소 계산이 간단하다.
- 단점 :
- 내부 단편화가 발생할 수 있다. 프로세스의 메모리 요구량과 할당된 블록의 크기 차이로 인해 메모리 공간이 낭비될 수 있다.
- 메모리 공간을 2의 거듭제곱 크기로 분할하므로, 메모리 공간의 활용도가 떨어질 수 있다.
Paging(분산 적재)
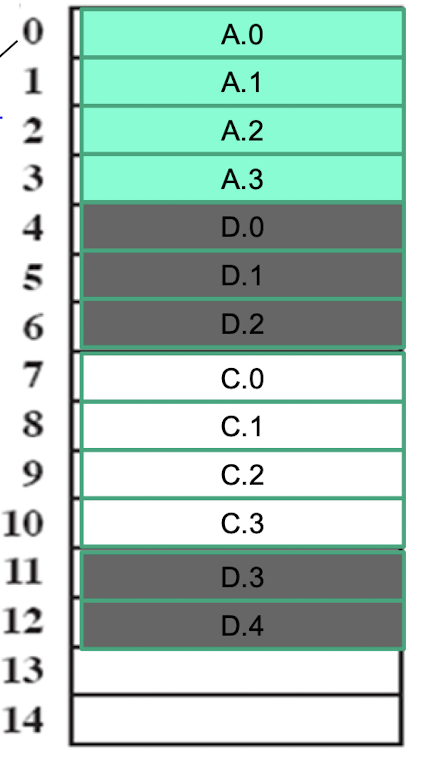
페이지와 페이지 프레임:
- 물리 메모리는 고정된 크기의 블록으로 나누어지며, 이를 페이지 프레임(Page Frame)이라고 한다.
- 프로세스의 주소 공간도 같은 크기의 블록으로 나누어지며, 이를 페이지(Page)라고 한다.
- 일반적으로 페이지와 페이지 프레임의 크기는 4KB 또는 그 배수로 설정된다.
주소 변환:
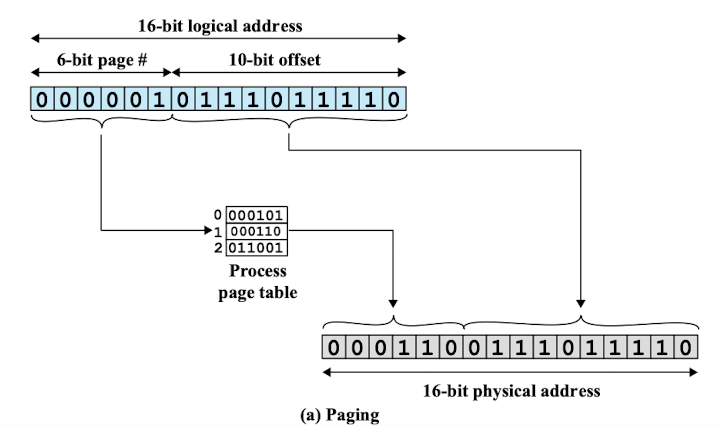
- 가상 주소는 페이지 번호(Page Number)와 페이지 오프셋(Page Offset)으로 구성된다.
- 페이지 번호는 해당 페이지가 위치한 페이지 테이블의 인덱스를 나타낸다.
- 페이지 오프셋은 페이지 내에서의 상대적인 주소를 나타낸다.
- 주소 변환 과정에서 페이지 번호를 통해 페이지 테이블을 참조하여 해당 페이지가 물리 메모리의 어느 페이지 프레임에 로드되어 있는지 확인한다.
페이지 테이블:
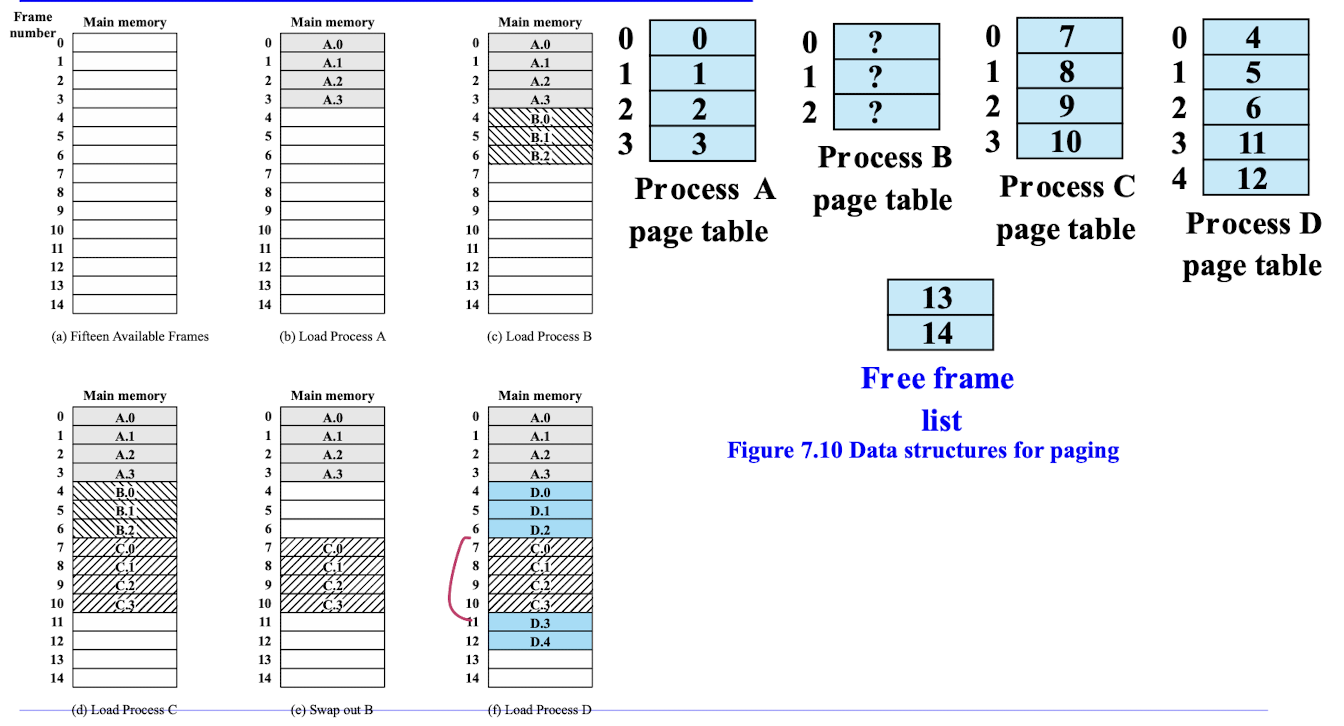
- 페이지 테이블은 각 프로세스마다 독립적으로 유지되는 자료구조이다.
- 페이지 테이블은 가상 페이지 번호와 해당 페이지가 로드된 물리 페이지 프레임 번호의 매핑 정보를 저장한다.
- 페이지 테이블의 엔트리는 페이지가 메모리에 존재하는지, 접근 권한, 수정 여부 등의 정보를 포함한다.
- 페이지 폴트(Page Fault):
- 프로세스가 접근하려는 페이지가 현재 물리 메모리에 로드되어 있지 않은 경우, 페이지 폴트가 발생한다.
- 페이지 폴트가 발생하면 운영체제는 해당 페이지를 디스크에서 메모리로 로드하고, 페이지 테이블을 업데이트한다.
- 페이지 폴트 처리는 프로세스 실행을 잠시 중단시키고, 페이지 로딩이 완료된 후 다시 실행을 재개한다.
- Address Translation
- 논리 주소를 실제 메모리 주소로 변환하기 위해 필요한 과정
- Page size를 2의 배수로 함으로써 상대 주소와 논리주소가 같고, HW적으로 효율적인 계산을 한다.
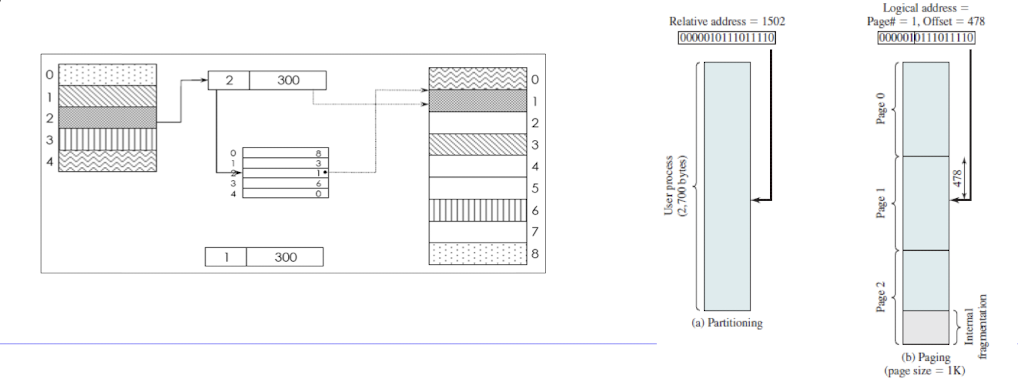
Segmentation(가변 길이 분산 적재)
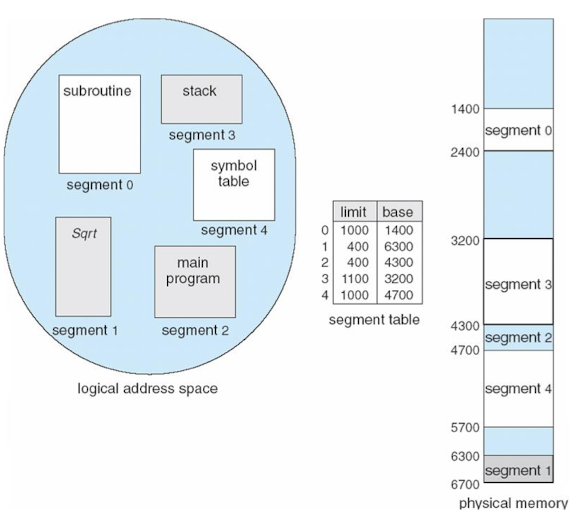
- 메모리 관리 기법 중 하나로, 프로그램을 논리적인 단위인 세그먼트(Segment)로 나누어 관리하는 방식이다.
- 각 세그먼트는 프로그램의 특정 기능이나 데이터를 나타내며, 크기가 가변적일 수 있다.
Segmentation은 프로그램의 논리적 구조를 반영하여 메모리를 할당하고 보호한다.
세그먼트(Segment):
- 프로그램은 논리적인 단위인 세그먼트로 나누어진다.
- 각 세그먼트는 코드, 데이터, 스택 등 프로그램의 서로 다른 부분을 나타낸다.
- 세그먼트의 크기는 가변적이며, 프로그램의 요구사항에 따라 다를 수 있다.
세그먼트 테이블:
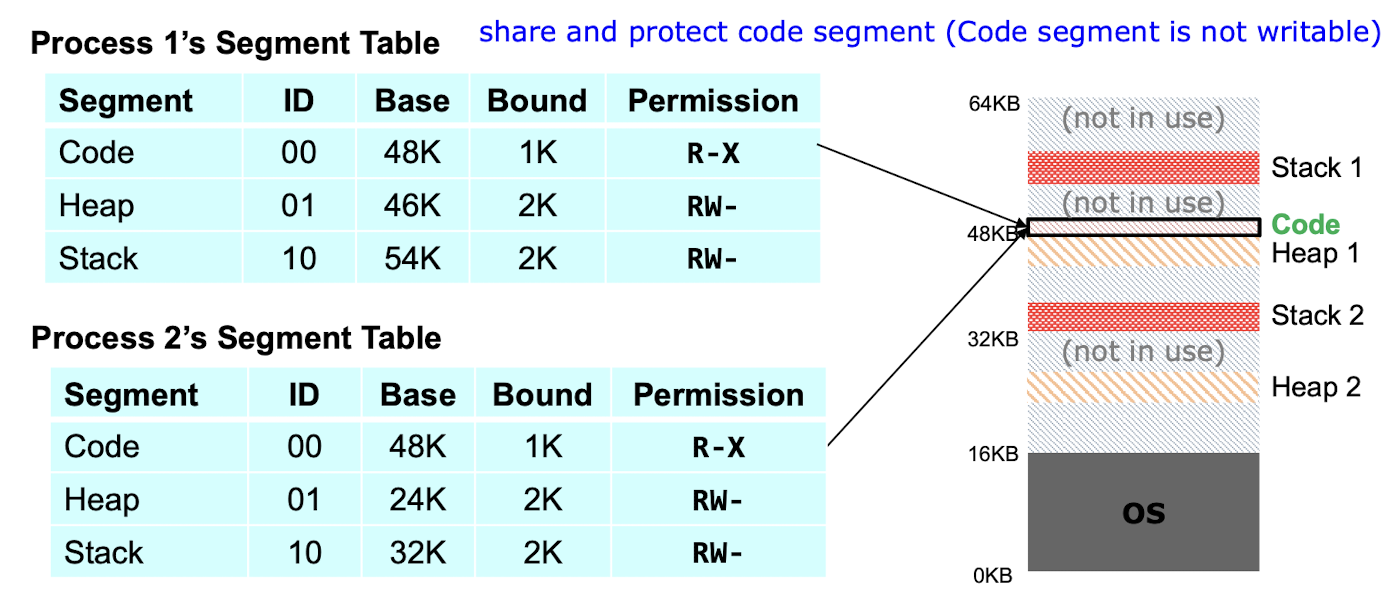
- 세그먼트 테이블은 각 세그먼트의 정보를 저장하는 자료구조이다.
- 세그먼트 테이블의 엔트리는 세그먼트의 기준 주소(Base Address)와 세그먼트의 크기(Limit)를 포함한다.
- 각 프로세스마다 독립적인 세그먼트 테이블을 가지고 있다.
주소 변환:
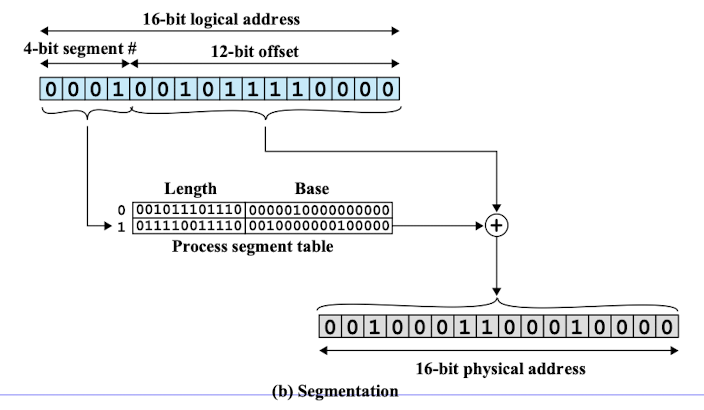
- 논리 주소는 세그먼트 번호와 세그먼트 내에서의 오프셋으로 구성된다.
- 주소 변환 과정에서 세그먼트 번호를 통해 세그먼트 테이블을 참조하여 해당 세그먼트의 기준 주소를 얻는다.
- 기준 주소에 오프셋을 더하여 실제 물리 주소를 계산한다.
- 메모리 보호:
- 세그먼트 테이블의 엔트리에는 세그먼트의 보호 정보도 포함된다.
- 각 세그먼트마다 읽기, 쓰기, 실행 권한 등을 설정할 수 있다.
- 세그먼트 범위를 벗어나는 접근이나 권한이 없는 접근은 보호 위반으로 처리된다.
- 장점
- 프로그램의 논리적 구조를 반영하여 메모리를 관리할 수 있다.
- 세그먼트 단위로 메모리 보호와 접근 제어가 가능하다.
- 공유 라이브러리나 코드 재사용이 용이하다.
- 단점
- 세그먼트의 크기가 가변적이므로 외부 단편화 문제가 발생할 수 있다.
- 세그먼트 테이블 관리를 위한 추가적인 메모리 공간과 관리 오버헤드가 발생한다.
- 최근 트렌드 : Paging 기법과 결합하여 사용되거나, Paging으로 대체되는 추세이다.
This post is licensed under CC BY 4.0 by the author.