Multi-Media-Computing.8 Recognition
멀티 미디어 컴퓨팅 공부
Multi-Media-Computing.8 Recognition
Recognition
- Recognition : 특정 오브젝트가 어디에 있는지 찾는 것
- Categorization : 어떤 종류의 오브젝트인지 분류하는 것
- Content-based image retrieval : 원하는 것을 찾기 위해 이미지로 검색하는 것
- Detection : 뭘 찾을지 사람이 알려주고 그것을 찾는 것
- 위와 같은 기술들은 feature matching을 통해 구한다는 공통점이 있다
Skin detection
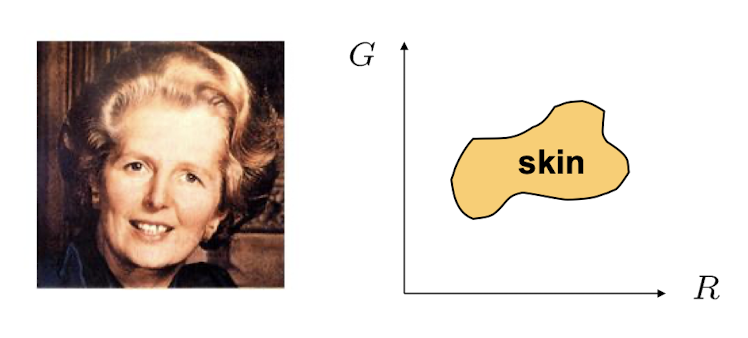
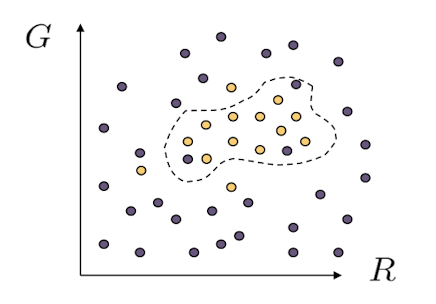
- RGB 값 중에 G와 B값을 그래프에 표시
- 위의 이미지에서 노란색 점이 스킨이라고 추정
- example을 만들어서 label된 training image를 만든다.
Skin classifier
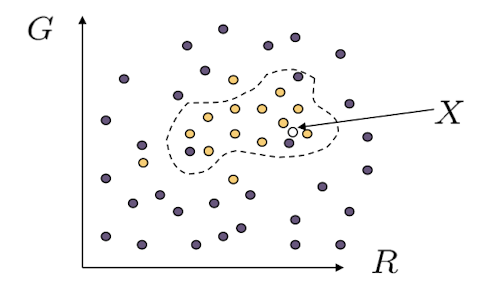
- 새로운 X 값이 들어왔을 때 해당 값이 skin인지 아닌지를 판별해야 한다면 아래와 같은 세가지 방법을 사용할 수 있다.
- Nearest neighbor : 가장 가까운 점과 같은 label을 갖는것
- 장점 : 심플하다
- 단점 : noisy한 값에 대해서 취약하다
- Find plane/curve that separates the two classes : decision boundary를 정의하는 SVM 방법
- over fitting 문제 : 학습 데이터에는 잘 동작하나 현실에서는 잘안되는 현상
- Data modeling : 각각의 데이터들에 대한 모델을 밝히는 것
- dense한 부분을 찾아내는 것
- skin/non-skin에 대한 2차원 히스토그램을 만들고 확률 분포를 2개 만든다.
- 이로써 새로운 값에 대한 확률 값을 얻을 수 잇게 된다.
- 장점 : machine에서 출력한 confidence를 수치적으로 나타낼 수 있다.
- 위의 3가지 방식의 특징과 장단점에 대해 잘 이해하는 것이 중요함.
Probability
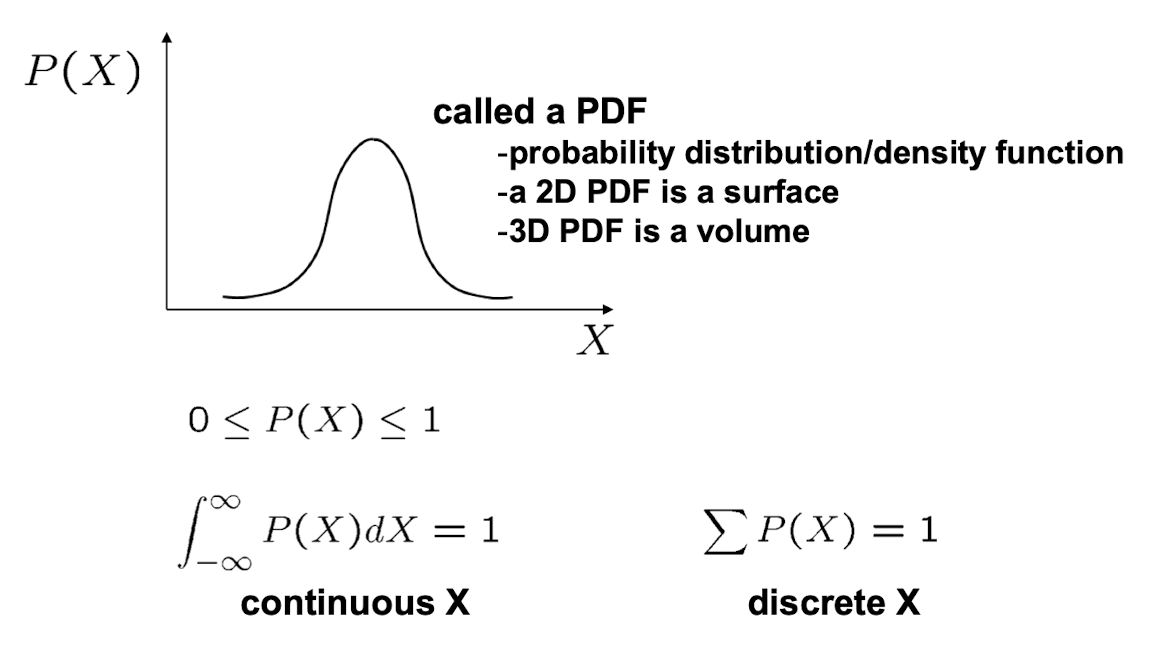
- X : random variable(확률 변수)
- P(X) : X가 특정 값을 달성할 확률
- 노이즈한 값을 측정할 때 확률 변수의 효용성이 좋다.
Probabilistic skin classification
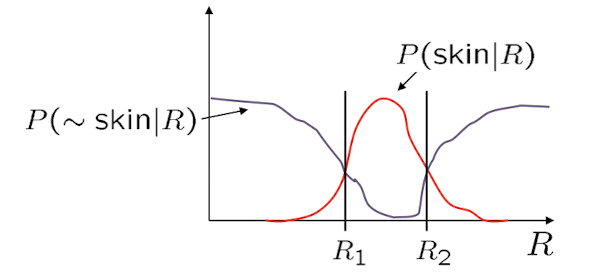
P(skin R) : R이 주어졌을 때 skin일 확률 P(~skin R) : R이 주어졌을 때 skin이 아닐 확률 위의 값을 구하기 위해서는 P(R skin)를 활용한다
Bayes rule
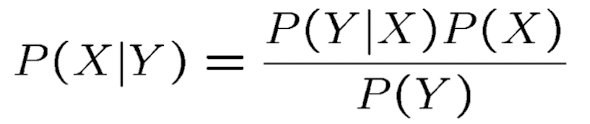

- posterior(사후 확률) : 데이터를 관찰한 후에 업데이트된 모델 파라미터(θ)에 대한 확률 분포이다.
- 실질적으로 원하는 확률 값
- likelihood(가능도) : 주어진 모델 파라미터(θ)에 대해 관찰된 데이터(X)의 확률을 나타내는 함수이다.
- 데이터들을 측정한 결과 확률 값
- 해석 가능한 모델
- prior(사전 확률) : 데이터를 관찰하기 전에 모델 파라미터(θ)에 대한 사전 지식이나 믿음을 나타내는 확률 분포이다.
- Domain knowledge에서 나온 확률(트레이닝 데이터에 국한하지 않은 도메인에서 일반적인 형태의 스킨 확률)
- train set으로부터 구할 수 있지만 해당 데이터에 편향될 수 있다.
normalization : P(R) = P(R skin)P(skin) + P(R ~skin)P(~skin) - 생성형 모델이라고 부른다.
Learning conditional PDF’s
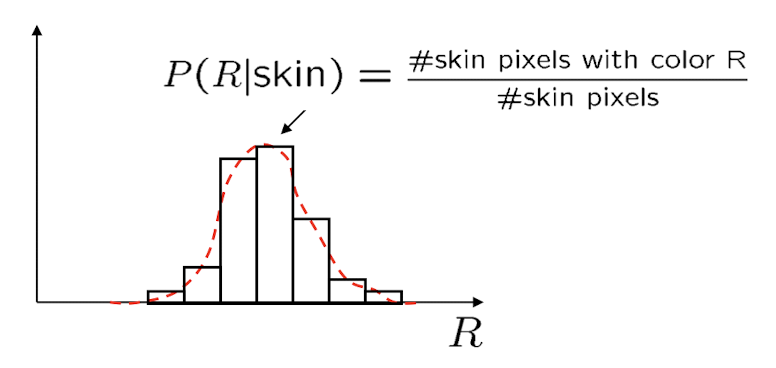
- 해당 skin에 대한 R의 히스토그램은 위와 같다.(Likelihood)
- 이 때 이 히스토그램을 그대로 쓰기보다는 분포 함수를 활용하는 것이 바람직하다.
- 보통 가우시안 분포로 모델링을 한다.
- miss value generation이 가능하다
- 특정 R값이 유실되어도 분포함수를 통해 generation 할 수 있다.
- 하지만 차원이 올라가면 정형화된 모델로 정의하기 어렵기 때문에 복잡해진다.
Bayesian estimation
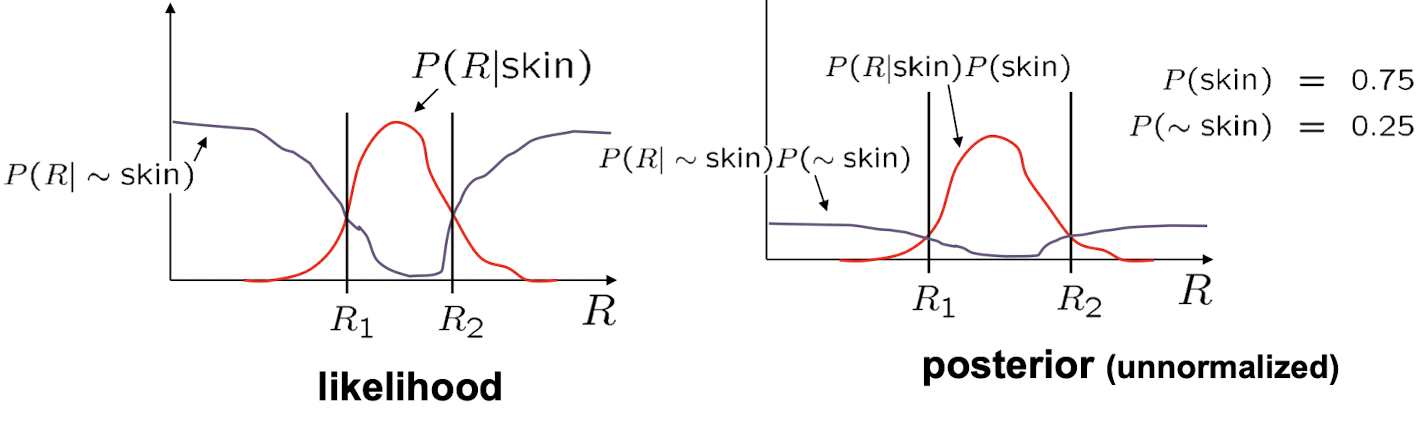
- 위의 이미지는 MAP(Maximum A Posterior)이다.
- domain knowledge를 반영한 것
- ML(Maximum Likelihood) : domain knowledge가 명확하지 않거나 없을 때 likelihood만 사용하는 경우
Visual Recognition
- Visual Recognition 알고리즘이 해야 되는 것들
- 이미지 또는 영상 분류
- 오브젝트 탐색
- 의미적인, 기하학적인 속성들을 추정
- 사람의 행동과 사건을 분류
Basic issue
- Representation : SIFT, 별자리 모델
- Learning : nearest neighbor
- Recognition
- Deep learning에서는 Representation과 Learning 단계를 합침
- intra-class variability : 확률적 모델을 씀으로써 극복 가능한 것
Learning
- 확습 과정에서 파라미터를 Likelihood를 maximize 하느냐(generative model), posterior를 Maximize하느냐(discrete model)에 따라 달라진다.
This post is licensed under CC BY 4.0 by the author.