Multi-Media-Computing.7 computer vision 2
멀티 미디어 컴퓨팅 공부
Multi-Media-Computing.7 computer vision 2
Model Fitting
- Model : 클래스가 가지고 있는 공통적인 특징
- Fitting : 모델의 파라미터에 변화를 주는 것
- ML : 학습
- y = f(x(입력값) : k(파라미터))
- k 값을 구하는 것이 학습이라고 함
- y = f(x(입력값) : k(파라미터))
- 빅데이터 : regression, fitting
- ML과 Fitting의 차이점 :
- ML : outlier가 좀 적다는 가정을 가지고 outlier가 있어도 전체적인 것에 부합하는 모델 파리미터를 구하는 것
- regression : outlier가 있어도 정상적인 값에 맞춰서 모델 파라미터를 구하는 것
- 공통점 : 모델 파라미터를 구하는 과정이다.
RANSAC(RANdom SAmple Consensus)
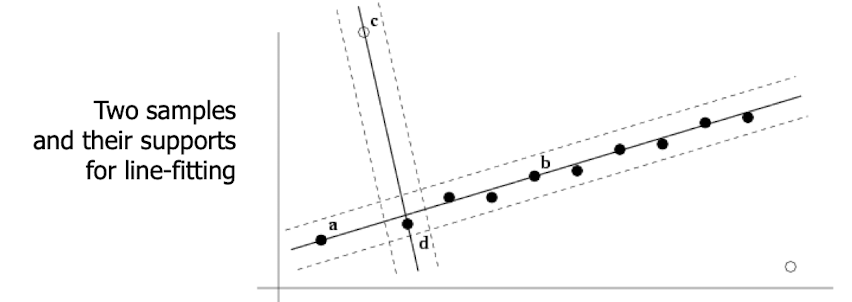
- Sample : 전체데이터의 일부를 뽑아쓴 것으로 만들어진 모델은 전체 데이터에서도 잘 부합할 것이다라는 가정
- Consensus : 직선 위에 정확히 올라와 있지 않아도 직선과 점의 distance에 대한 threshold를 지정하여 해당 threshold 이하이면 직선 위에 있는 것으로 생각한다.
- y = f(x : k) + e(e +- i)
- 랜덤하게 샘플하는 것
- 샘플에서 직선을 구하기 위해 minimal set을 뽑은 뒤 정의된 모델에 얼마나 많은 데이터들이 부합하는지 확인
- minimal set : 모델을 정의할 수 있는 최소 갯수
- 랜덤하게 계속 반복하며 결과값이 만족할 때 멈춤
- 최적해를 찾지 못하고 sub optimal을 찾는다.
- consensus(=support) : 일정 범위 내에 있는 점들
- inlier : consensus set에 포함되는 것
- outlier : inlier 외에 것
RANSAC 과정
- 필요한 최소한의 포인트 개수 n, 반복 횟수 k, 모델이 잘 맞는다고 판단하는 임계값 t, 선으로 간주할 근접 포인트 개수 d를 정한다.
- k번 반복하면서:
- 데이터에서 n개의 포인트를 무작위로 균일하게 선택하여 샘플을 만든다.
- 그 n개 포인트를 가지고 모델을 맞춘다.
- 샘플에 포함되지 않은 각 데이터 포인트에 대해, 포인트와 모델 사이의 거리를 계산하고, 거리가 t보다 작으면 그 점을 모델에 가까운(close) 점으로 간주한다.
- 모델에 가까운 점이 d개 이상이면 그 모델을 적합한 것으로 판단한다. 이때 그 가까운 점들을 모두 사용해 모델을 다시 맞춘다.
- k번 반복 후 가장 적합도가 높았던 모델을 최종 선택하되, 맞춤 오차를 기준으로 사용한다.
After RANSAC
- 가장 좋은 파라미터는 반드시 두점을 지나는 값이 아닐 수도 있다.
- RANSAC 후 나온 inlier들을 상대로 least squared fitting을 통해 차이를 minimal 할 수 있다.(post processing)
- inlier로 regression
- 장점
- General 하기 때문에 많은 상황에 사용될 수 있다
- 구현이 간단하다
- 단점
- outlier가 대부분이면 쓰기가 어렵다
Segmentation
- 객체를 정의하기 위한 요소
- proximity, similarity, continuation, common fate
- Image Segmentation 종류
- Clustering Methods
- Histogram-Based Methods
- Edge Detection Methods : 엣지 기반으로 찾는 것
- Graph Cut Methods
- Region Growing Methods : 영억을 확장 시키는 방법
- Level Set Methods
- Watershed Transformation : 물이 차오르는 것처럼 나누는 방법
- Model based Segmentation : 모델의 모양에 맞게 나누는 법
- Multi-scale Segmentation
- Neural Networks Segmentation : 인코더와 디코더를 활용한 최신 방법
Clustering Method
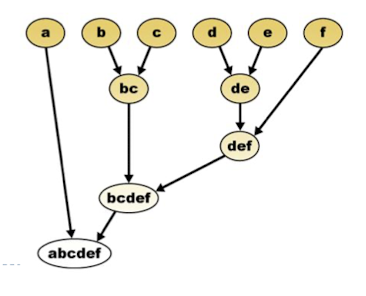
- 비슷한 것들끼리 그룹핑 하는 방법
- distance function이 필요함
- cues : color, regions, contours
- 픽셀 혹은 token(super pixel)을 그룹짓는다.
- 보통은 region growing 방식을 써서 덩어리를 모은다.
- Dendrogram
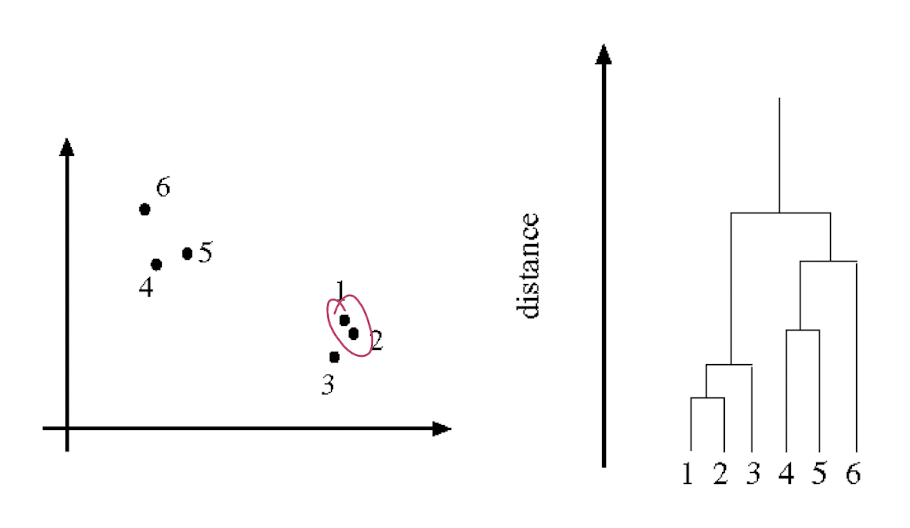
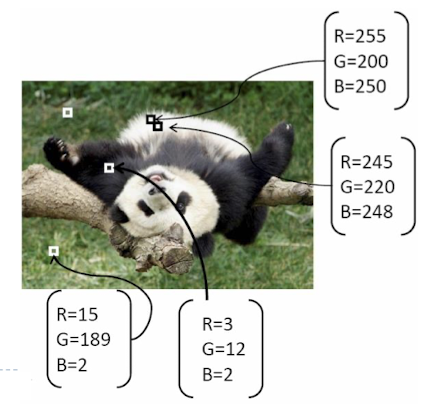
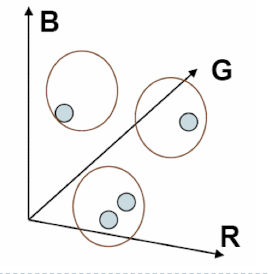
Feature space
- feature
- position
- color
- texture
- motion vector
- size
- feature vector(feature들을 묶어서 사용하는 것)
- feature space : 이러한 vector들을 표현하는 공간
- 이러한 특성을 수치화 하는 방법이다.
- filter bank
- filter bank response
- example1. intensity


- example2. RGB
k-Means Clustering
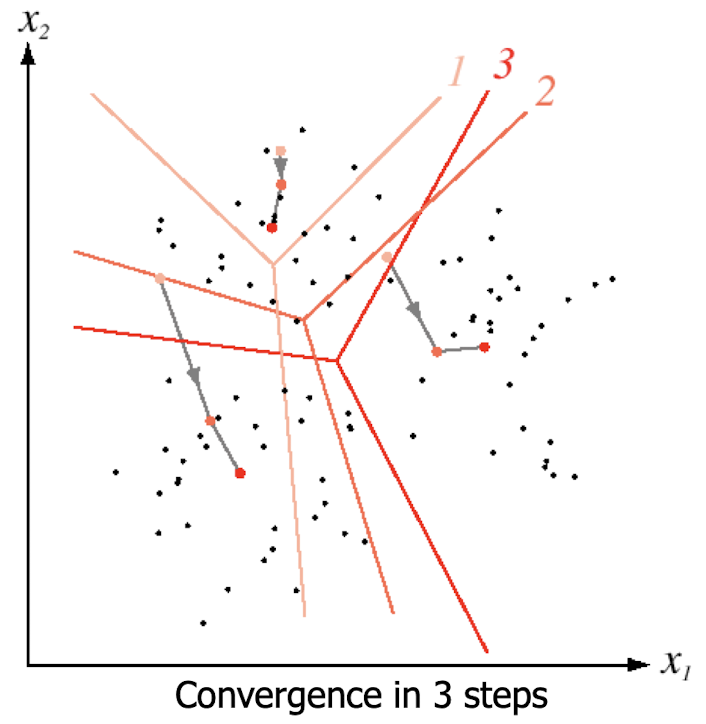
- k : 클러스터의 갯수
- 원리
- K개의 초기 중심점(centroid)을 임의로 선택한다.
- 각 데이터 포인트를 가장 가까운 중심점에 할당하여 K개의 클러스터를 형성한다.
- 각 클러스터의 중심점을 다시 계산합니다. 새로운 중심점은 해당 클러스터에 속한 모든 데이터 포인트의 평균으로 설정된다.
- 장점
- 심플하고, 빠르다
- 단점
- 영상에 모든 토큰을 completed connected graph를 만든다.
- 모든 edge에 affinity edge를 만든 뒤 weight를 설정한다
- weight 계산 방식을 잘 정의 해야된다.
- 그 뒤에 edge 값에 대한 threshold를 정하고 끊음으로써 cluster를 만든다.
- 적절히 끊는 알고리즘 또한 정의하기 어렵다.
- graphcut 알고리즘이 딥러닝 이전에 가장 최신 방법이다.
This post is licensed under CC BY 4.0 by the author.