Database 9. stored procedure
데이터 베이스 이론 공부
Database 9. stored procedure
- MySQL 문법을 기준으로 서술한다.
stored procedure
- 사용자가 정의한 프로시저
- RDBMS에 저장되고 사용되는 프로시저
- 구체적인 하나의 태스크(task)를 수행한다.
stored procedure 예제 1
1
2
3
4
5
6
7
8
9
10
delimiter $$
CREATE PROCEDURE product(IN a int, IN b int, OUT result int) -- input과 output을 적어줘야 한다.
BEGIN
SET result = a * b;
END
$$
delimiter ;
call product(5, 7, @result);
select @result;
stored procedure 예제 2
1
2
3
4
5
6
7
8
9
10
11
12
13
delimiter $$
CREATE PROCEDURE swap(INOUT a int, INOUT b int) -- input과 output을 적어줘야 한다.
BEGIN
set @temp = a;
set a = b;
set b = @temp;
END
$$
delimiter ;
set @a = 5, @b = 7;
call swap(@a, @b);
select @a, @b;
stored procedure 예제 3
1
2
3
4
5
6
7
8
9
delimiter $$;
CREATE PROCEDURE get_dept_avg_salary()
BEGIN
select dept_id, avg(salary)
from employee
group by dept_id;
END
$$
delimiter ;
stored function 예제 4
- 사용자가 프로필 닉네임을 바꾸면 이전 닉네임을 로그에 저장하고 새 닉네임을 업데이트하는 프로시저를 작성
1
2
3
4
5
6
7
8
9
10
11
12
delimiter $$
CREATE PROCEDURE change_nickname(user_id int, new_nick varchar(30)) -- IN, OUT 등이 적혀있지 않으면 default로 IN
BEGIN
insert into nickname_logs(
select id, nickname, now() from users where id = user_id
);
update users set nickname = new_nick where id = user_id;
END
$$
delimiter ;
call change_nickname(1, 'ZIDANE');
- 이외에도 조건문을 통해 분기처리를 하거나
- 반복문을 수행하거나
- 에러를 핸들링하거나 에러를 발생 시키는 등의 로직을 정의할 수 있다.
stored procedure vs stored function
| - | stored procedure | stored function |
|---|---|---|
| create 문법 | create procedure | create function |
| return 키워드로 값 반환 | 불가능(SQL server는 상태코드 반환용으로는 사용 가능) | 가능(MySQL, SQL server는 값 반환하려면 필수) |
| 파라미터로 값(들)반환 | 가능(값(들)을 반환하려면 필수) | 일부 가능 |
| 값을 꼭 반환해야 하나? | 필수 아님 | 필수 |
| SQL Statement에서 호출 | 불가능 | 가능 |
| transaction | 가능 | 대부분 불가능(oracle의 경우 가능) |
| 주된 사용 목적 | business logic | computation |
- 위의 차이들 외에도 아래와 같은 차이가 존재함
- 다른 function/procedure를 호출할 수 있는지
- result-set(table)을 반환할 수 있는지
- precompiled execution plan을 만드는지
- try-catch를 사용할 수 있는지
3-tier architecture에서 stored procedure의 의미
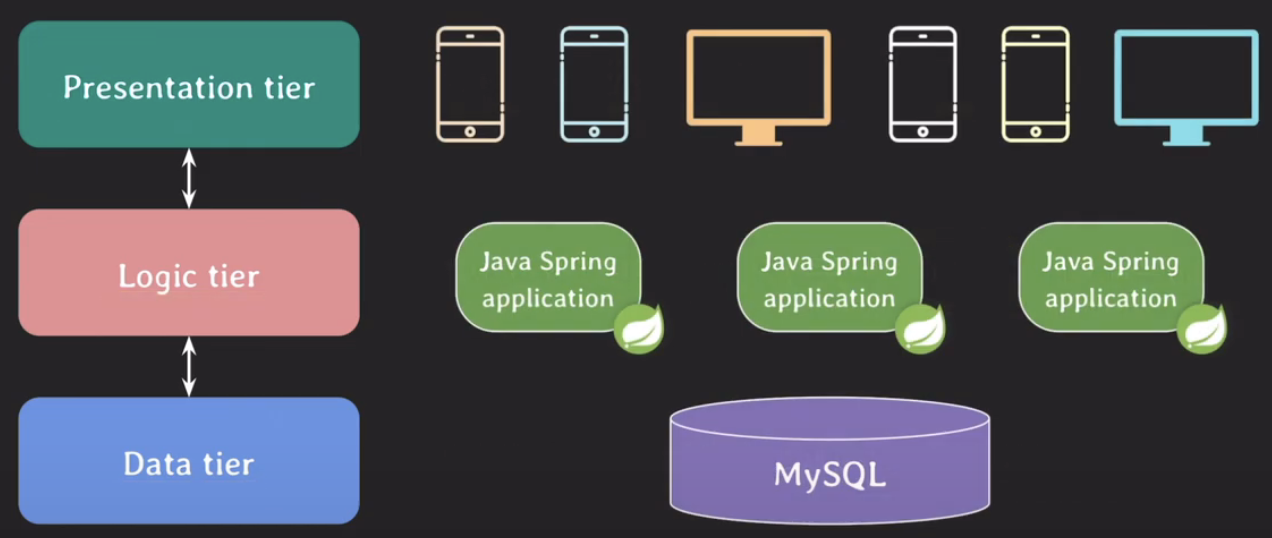
- 3-tier architecture의 구성
- Presentation tier : 사용자에게 보여지는 부분을 담당하는 tier
- Logic tier : 서비스와 관련된 기능과 정책 등등 비즈니스 로직을 담당하는 tier
- Data tier : 데이터를 저장하고 관리하고 제공하는 역할을 하는 tier
- 위와 같은 Data tier에서 stored procedure를 활용해 business logic을 구현할 수 있다.
stored procedure의 장단점
- 장점
- application에 transparent하게 동작할 수 있다.
- transparent : 무언가 변경이 생겨도 바뀌기 전에 사용 중이던 부분들은 추가적인 변경이 필요하지 않다.
- network traffic을 줄여서 응답 속도를 향상시킬 수 있다.
- 여러 서비스에서 재사용 가능하다.
- 민감한 정보에 대한 접근을 제한할 수 있다.
- database의 table에 직접적인 접근은 막지만 procedure에 대한 접근을 허용하는 방식
- application에 transparent하게 동작할 수 있다.
- 단점
- stored procedure를 쓰게 되면 유지 관리 보수 비용이 커진다.
- 소스 코드와 프로시저 코드를 둘 다 관리해줘야 됨
- 버전 관리를 둘 다 해줘야 한다.
- 프로시저 관련 문법을 잘 알아야 한다.
- DB 서버를 추가하는 것은 간단한 작업이 아니다.
- stored procedure가 언제나 transparent인건 아니다.(또한 transparent하다고 무조건 좋은 것도 아니다.)
- 잘못된 로직의 파장이 넓어질 수 있다.
- 소스 코드에 로직이 있는 경우보다 오히려 손이 더 많이 갈 수 있다.
- 재사용 가능하다는 것이 양날의 검이 될 수 있다.
- 통제되지 않는 사용으로 모두에게 문제가 발생할 수 있다.
- 비즈니스 로직을 소스 코드에 두고도 응답 속도를 향상 시킬 수 있다.
- insert와 update를 동시 진행 가능하게 하거나 (thread pool을 활용하여)
- redis cache를 활용하여 응답 속도를 향상 시킬 수 있다.
- stored procedure가 민감한 정보에 대한 접근을 완벽히 제한할 수 없다.
- DB 혹은 테이블 접근을 막으면 개발 및 CS 업무의 신속함이 떨어진다.
- stored procedure를 쓰게 되면 유지 관리 보수 비용이 커진다.
This post is licensed under CC BY 4.0 by the author.