Computer-Network 7. Unicast Routing Protocols
컴퓨터 네트워크 공부 기록
Computer-Network 7. Unicast Routing Protocols
Unicast Routing protocol
AS(Autonomous System)
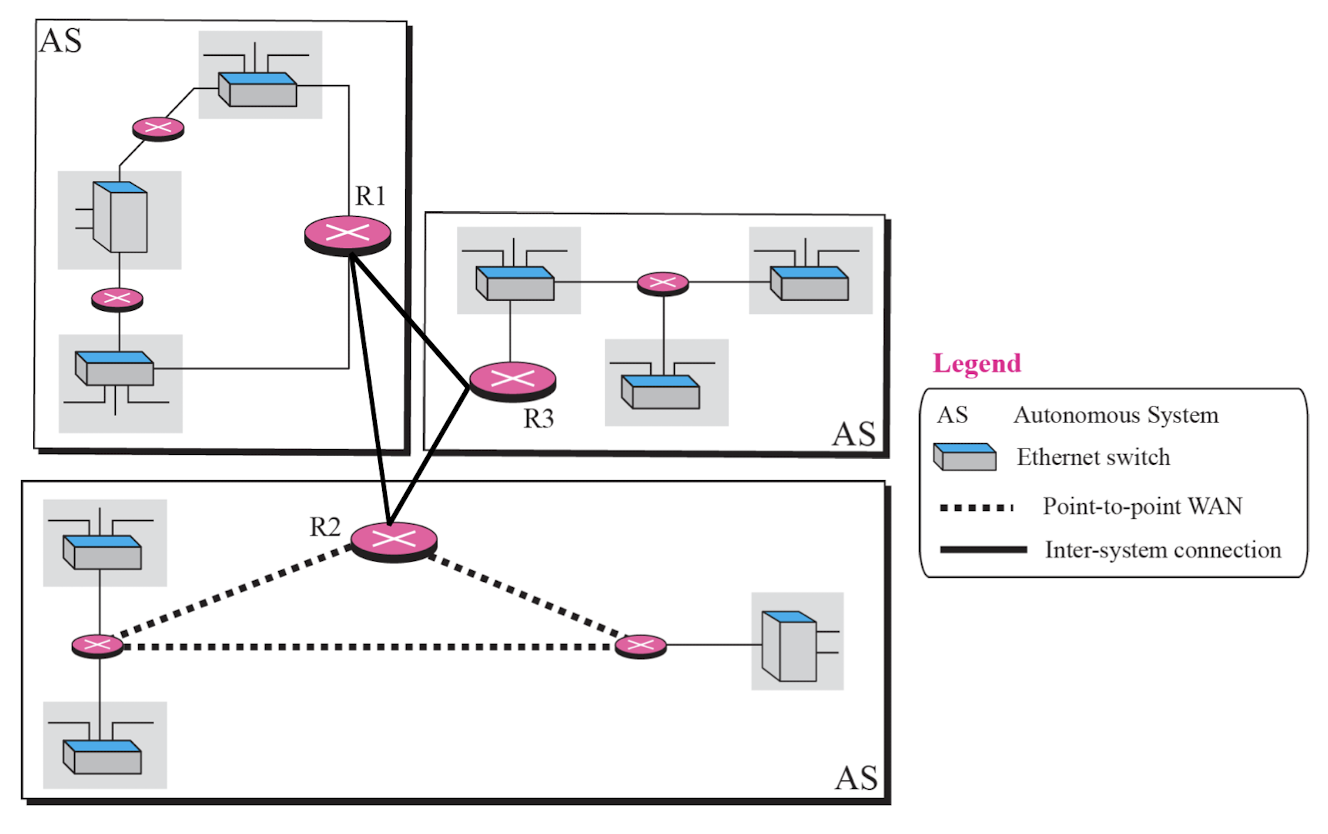
- 인터넷에서 단일 관리 주체 하에 운영되는 독립적인 라우팅 도메인을 의미한다.
- AS는 자체적인 라우팅 정책을 가지고 있으며, 다른 AS와 상호 접속하여 인터넷 트래픽을 교환한다.
- 특징
- 고유 식별자: 각 AS는 전 세계적으로 고유한 AS Number(ASN)로 식별된다.
- 독립적 라우팅: AS 내부에서는 자체적인 라우팅 프로토콜(IGP, Interior Gateway Protocol)을 사용하여 경로를 설정하고, 외부와는 BGP(Border Gateway Protocol)를 통해 라우팅 정보를 교환한다.
- 트래픽 교환: AS들은 서로 피어링(peering) 또는 트랜짓(transit) 계약을 맺어 트래픽을 주고받는다.
- 관리 주체: ISP, 대기업, 학술기관, 정부기관 등 다양한 조직이 AS를 운영할 수 있다.
Intra-domain Routing Protocol
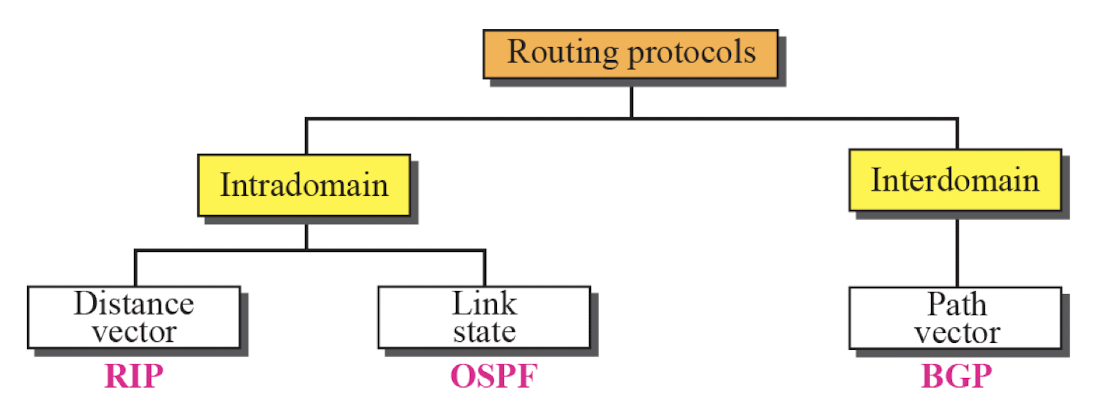
RIP(Routing Information Protocol)
- AS 내부에서 라우팅 정보를 교환하기 위해 사용되는 IGP(Interior Gateway Protocol) 중 하나이다.
- 거리 벡터(Distance vector) 알고리즘을 기반으로 하며, 작은 규모의 네트워크에 적합한 프로토콜이다.
- 특징
- 거리 벡터 알고리즘: RIP는 각 라우터가 자신과 직접 연결된 이웃 라우터들과 라우팅 정보를 주기적으로 교환한다.
- 이 때, 각 경로의 메트릭(metric)은 홉 카운트(hop count)로 표현되며, 이는 목적지까지 거쳐야 할 라우터의 수를 의미한다.
- 제한된 홉 카운트: RIP는 홉 카운트의 최대값을 15로 제한한다. 따라서 16홉 이상 떨어진 네트워크는 도달할 수 없는 것으로 간주된다.
- 이는 RIP의 확장성을 제한하는 요인 중 하나이다.
- 주기적인 업데이트: RIP는 일반적으로 30초마다 라우팅 테이블을 이웃 라우터와 교환한다. 이를 통해 네트워크 토폴로지 변화를 감지하고 대응할 수 있다.
- 단순한 설정: RIP는 설정이 간단하며, 네트워크 관리자가 라우팅 테이블을 수동으로 구성할 필요가 적다.
- 하지만 이는 동시에 RIP의 최적화 능력이 제한적임을 의미하기도 한다.
- 느린 수렴 속도: 네트워크 토폴로지가 변경되면 RIP는 홉 카운트 정보가 네트워크 전체에 전파되어 모든 라우터의 라우팅 테이블이 안정화될 때까지 시간이 걸린다.
- 이 수렴 과정이 비교적 느린 편이다.
- 거리 벡터 알고리즘: RIP는 각 라우터가 자신과 직접 연결된 이웃 라우터들과 라우팅 정보를 주기적으로 교환한다.
- 소규모 네트워크에서 간단히 구현할 수 있다는 장점이 있지만, 확장성과 수렴 속도 측면에서는 한계를 가지고 있다.
- 따라서 대규모 네트워크에서는 OSPF나 EIGRP 같은 보다 발전된 IGP를 사용하는 것이 일반적이다.
Distance vector Routing
- AS안에서의 경로 설정
- Bellman-Ford algorithm 기반으로 만들어졌다.
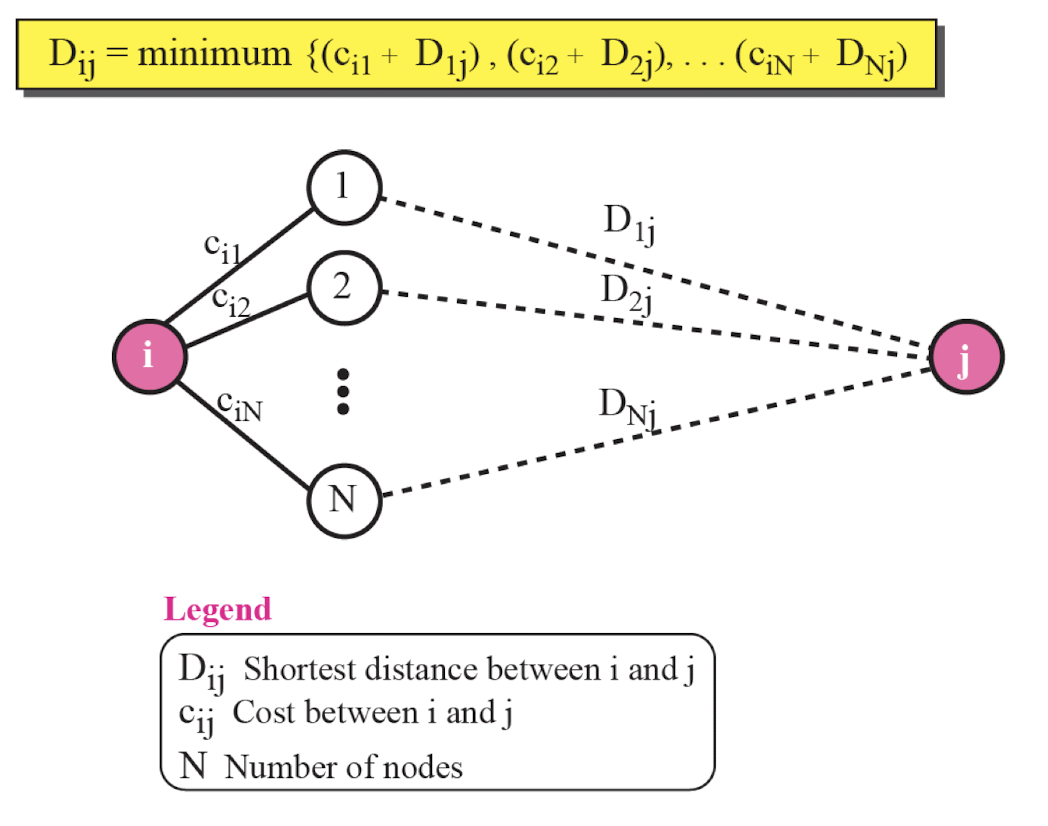
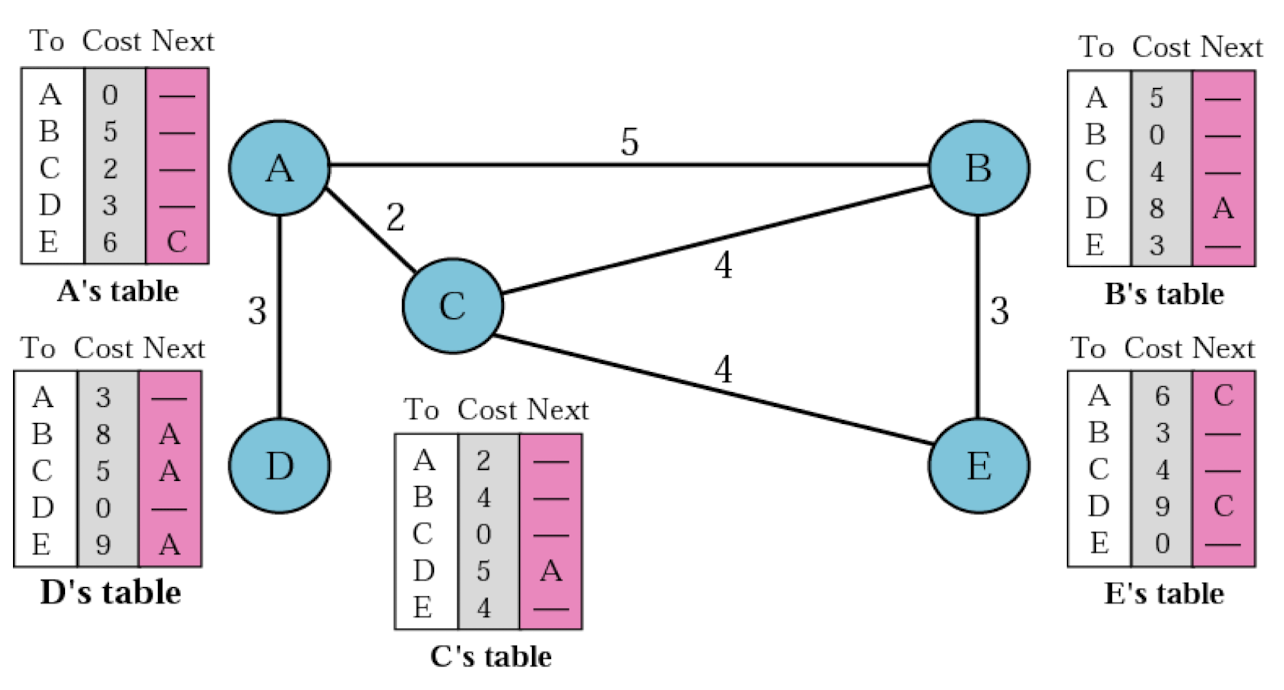
Distance vector Example
- 노드 : router, host
- 간선의 가중치 : hop count
- Initialization for Table(최초 테이블)
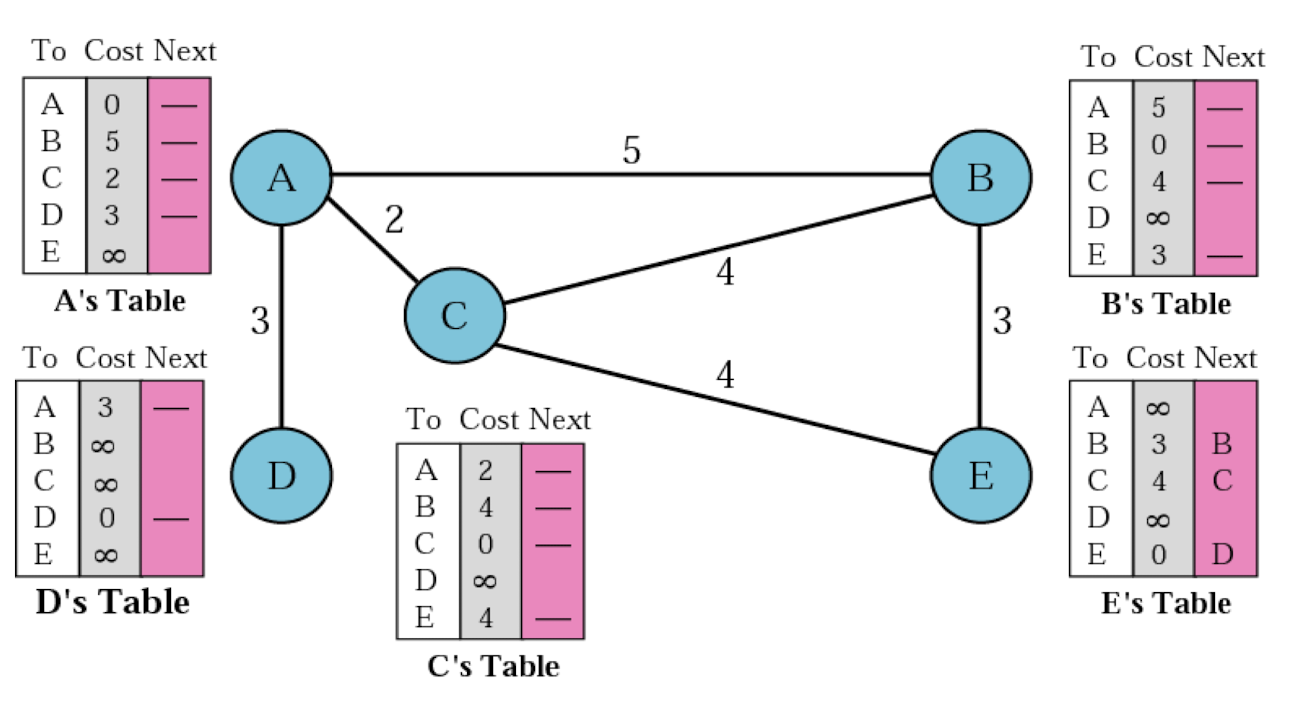
- 초기에는 Direct하게 연결된 것들만 알고 있는 상태로 시작한다.
- 서로 정보를 주고 받으며 자신보다 더나은 정보를 가지고 있으면 갱신한다.
- Updating Table
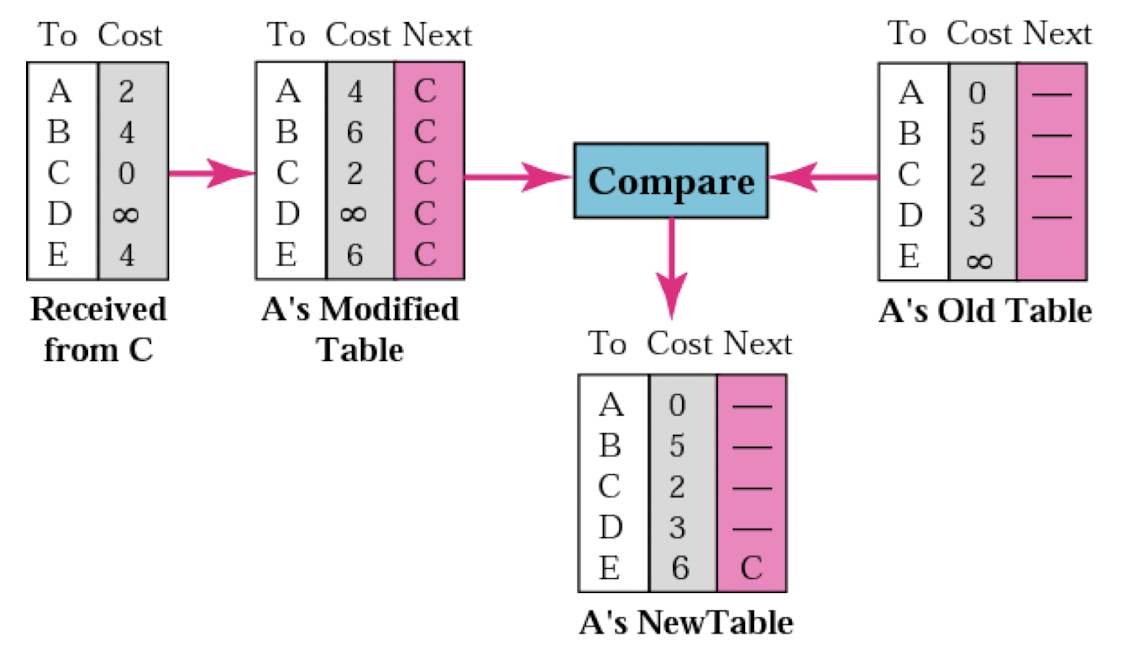
- 만약 next가 똑같으면 최신 정보를 업데이트한다.
- 상황이 바뀌었다고 판단하고 cost가 더 높아도 최신 정보를 갱신한다.(위의 이미지에서 A의 table에 B의 cost는 6으로 바뀌어야 한다)
- 만약 next가 똑같으면 최신 정보를 업데이트한다.
- Result of Table(최종 테이블)
Two-node instability
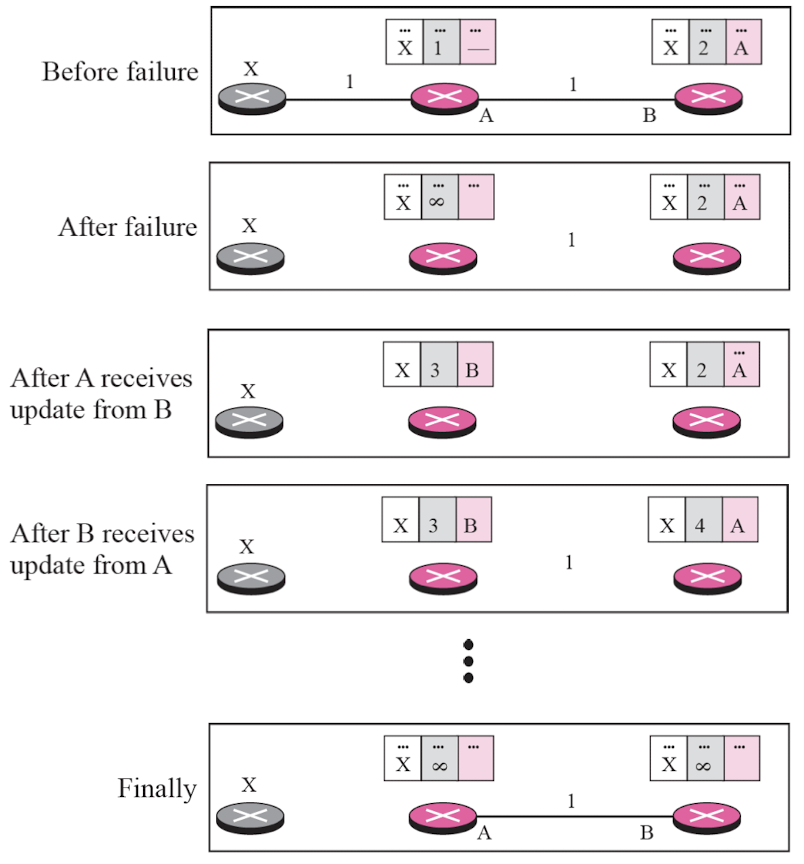
- RIP에서 발생할 수 있는 문제 중 하나로, 두 개의 라우터 사이에서 라우팅 루프(routing loop)가 형성되어 네트워크 불안정을 야기하는 현상이다.
- 거리 벡터 알고리즘과 홉 카운트 제한으로 인해 발생하는 현상이다.
- 발생 과정
- 라우터 A와 B가 직접 연결되어 있고, 각각 네트워크 C에 대한 경로 정보를 가지고 있다고 가정한다.
- 어떤 이유로 라우터 A가 네트워크 C에 대한 경로를 잃어버리면, 해당 경로를 라우팅 테이블에서 제거한다.
- 라우터 A는 라우터 B에게 네트워크 C에 대한 경로가 무한대(홉 카운트 16)라는 정보를 전파한다.
- 라우터 B는 이 정보를 받아들이고, 자신의 라우팅 테이블에서 네트워크 C에 대한 기존 경로를 무한대로 업데이트한다.
- 라우터 B는 다시 라우터 A에게 네트워크 C에 대한 경로 정보를 전파하는데, 이 때 메트릭 값은 무한대에서 1 증가한 값이다.
- 라우터 A는 이 정보를 받아들이고, 네트워크 C에 대한 경로를 라우터 B를 통해 도달할 수 있는 것으로 판단한다.
- 이 과정이 계속 반복되면서 라우터 A와 B 사이에 라우팅 루프가 형성되고, 네트워크 C에 대한 패킷이 두 라우터 사이에서 무한히 순환하게 된다.
- 해결 방법
- Split Horizon : 라우터는 어떤 인터페이스로부터 학습한 경로 정보를 동일한 인터페이스를 통해 다시 전파하지 않는 방식
- Route Poisoning : 무한대 메트릭 대신 네트워크에 대한 경로가 사용 불가능함을 명시적으로 알리기 위해 홉 카운트를 16으로 설정한다.
- 이렇게 “중독된(poisoned)” 경로 정보를 받은 라우터는 해당 경로를 즉시 폐기처리하고, 다른 라우터에게 전파하지 않는다.
- Holddown Timer : 라우터가 특정 경로에 대해 메트릭 증가 업데이트를 받으면, 해당 경로를 즉시 업데이트하지 않고 일정 시간(holddown 시간) 동안 기다린다.
- 이 시간 동안 동일한 경로에 대해 더 나은 메트릭 값을 가진 업데이트를 받으면, 해당 업데이트를 적용한다. 그렇지 않은 경우 원래의 메트릭 증가 업데이트를 수락한다.
Three-node instability
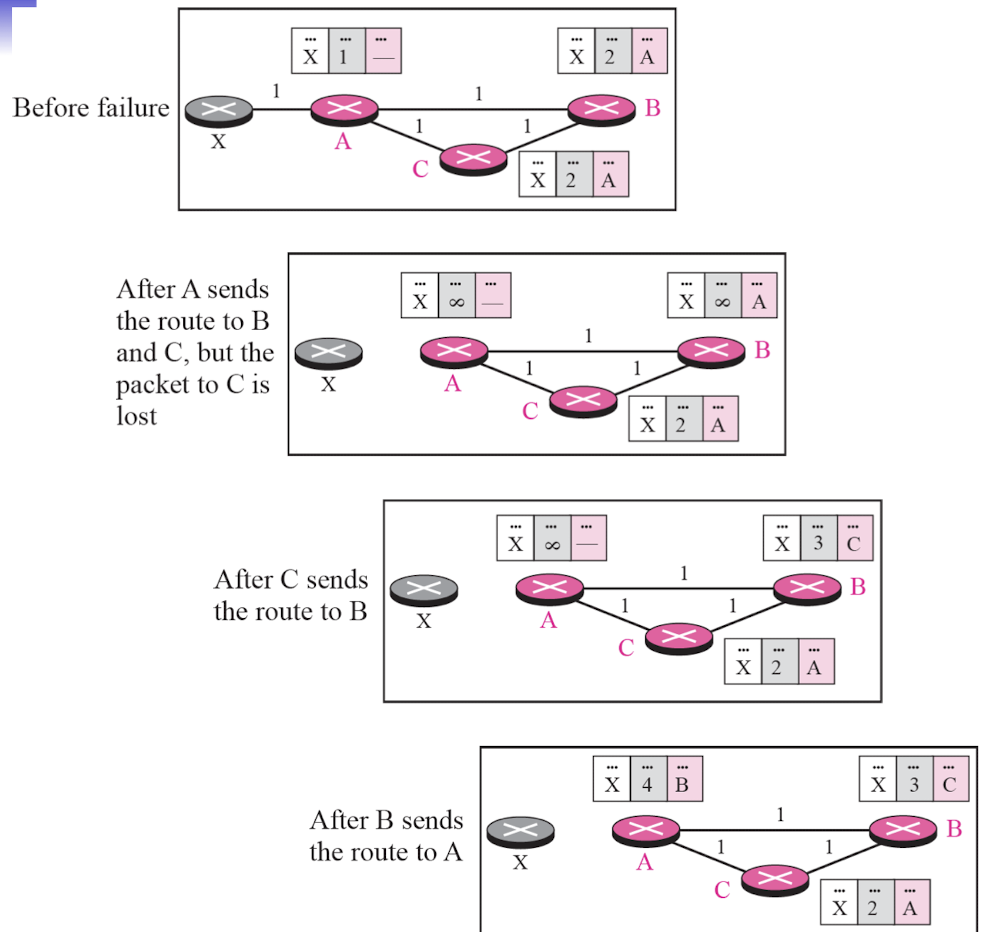
- 발생 과정
- 라우터 A, B, C가 직렬로 연결되어 있고, 라우터 C는 네트워크 D에 연결되어 있다고 가정한다.
- 초기에는 모든 라우터가 네트워크 D에 대한 경로 정보를 가지고 있다.
- 어떤 이유로 라우터 C와 네트워크 D 사이의 링크가 끊어지면, 라우터 C는 네트워크 D에 대한 경로를 무한대 메트릭(홉 카운트 16)으로 업데이트한다.
- 라우터 C는 이 정보를 라우터 B에게 전파하고, 라우터 B는 다시 라우터 A에게 전파한다.
- 문제는 라우터 B가 라우터 C로부터 받은 무한대 메트릭 정보를 라우터 A에게 전파하기 전에, 라우터 A로부터 기존의 네트워크 D에 대한 경로 정보를 수신하는 경우에 발생한다.
- 이 경우 라우터 B는 라우터 A가 제공한 경로 정보를 더 선호하게 되고, 자신의 라우팅 테이블을 그에 따라 업데이트한다.
- 하지만 라우터 A는 여전히 라우터 B를 통해 네트워크 D에 도달할 수 있다고 판단하고 있으므로, 세 라우터 사이에 라우팅 루프가 형성된다.
- 해결 방법
- Split Horizon with Poison Reverse
- Split Horizon 규칙에 따라 라우터가 자신이 학습한 경로 정보를 동일한 인터페이스로 다시 전파하지 않는다.
- 라우터는 자신이 무한대 메트릭을 가진 경로 정보를 수신한 인터페이스로는 명시적으로 무한대 메트릭을 전파한다.
- Split Horizon with Poison Reverse
OSPF
- 링크 상태 라우팅 프로토콜(Link-State Routing Protocol)의 일종으로, 대규모 네트워크에서 효율적이고 빠른 라우팅을 제공하기 위해 설계되었다.
- OSPF는 RFC 2328에 정의되어 있으며, 현재 버전 2가 널리 사용되고 있다.
주요 특징
- 링크 상태 알고리즘:
- OSPF는 링크 상태 알고리즘을 사용하여 네트워크 토폴로지를 파악하고 최적의 경로를 계산한다.
- 각 OSPF 라우터는 자신과 직접 연결된 링크의 상태 정보를 수집하고, 이를 Link-State Advertisement(LSA)라는 패킷에 담아 네트워크 전체에 플러딩한다.
- 모든 라우터는 수신한 LSA를 기반으로 네트워크 토폴로지를 나타내는 Link-State Database(LSDB)를 구축한다.
- 각 라우터는 LSDB를 사용하여 Dijkstra 알고리즘을 통해 최단 경로 트리(Shortest Path Tree)를 계산하고, 이를 기반으로 라우팅 테이블을 생성한다.
- 계층적 네트워크 구조:
- OSPF는 네트워크를 Area라는 작은 단위로 분할하여 계층적으로 관리한다.
- Area는 논리적으로 그룹화된 네트워크 세그먼트로, 일반적으로 Area 0(Backbone Area)를 중심으로 구성된다.
- 각 Area 내부에서는 자체적인 LSDB를 유지하고, Area 경계 라우터(Area Border Router, ABR)를 통해 다른 Area와 정보를 교환한다.
- 이러한 계층적 구조는 네트워크의 확장성을 높이고, 라우팅 업데이트 트래픽을 줄이는 데 도움이 된다.
- 링크 상태 알고리즘:
- 다양한 네트워크 타입 지원:
- OSPF는 브로드캐스트, 포인트-투-포인트, 포인트-투-멀티포인트, 비 브로드캐스트 멀티액세스(NBMA) 등 다양한 네트워크 타입을 지원한다.
- 각 네트워크 타입에 따라 OSPF는 적절한 인접 관계 형성 및 LSA 전파 메커니즘을 사용한다.
빠른 수렴:
- OSPF는 네트워크 토폴로지 변화에 빠르게 적응하고 수렴할 수 있도록 설계되었다.
- 라우터는 Hello 패킷을 주기적으로 교환하여 인접 라우터의 가용성을 모니터링한다.
- 링크 상태 변화가 감지되면 해당 라우터는 즉시 LSA를 생성하고 전파하여 빠른 수렴을 촉진한다.
인증 및 보안:
- OSPF는 라우팅 업데이트의 무결성과 인증을 보장하기 위한 메커니즘을 제공한다.
- 각 OSPF 패킷은 MD5 또는 SHA 기반의 인증을 통해 보호될 수 있다.
- 이를 통해 악의적인 라우터가 네트워크에 참여하거나 라우팅 정보를 조작하는 것을 방지할 수 있다.
부하 분산:
- OSPF는 Equal-Cost Multi-Path(ECMP) 기능을 지원하여 동일한 비용의 여러 경로를 동시에 사용할 수 있다.
- 이를 통해 네트워크 부하를 분산시키고 대역폭 활용도를 높일 수 있다.
- 다양한 확장 기능:
- OSPF는 다양한 확장 기능을 제공하여 프로토콜의 유연성과 기능성을 높인다.
- 예를 들어, Traffic Engineering(TE) 확장을 통해 네트워크 자원을 최적으로 활용하고, 특정 경로에 트래픽을 할당할 수 있다.
- 또한, Multicast 확장(MOSPF)을 통해 효율적인 멀티캐스트 라우팅을 지원한다.
Link State Routing
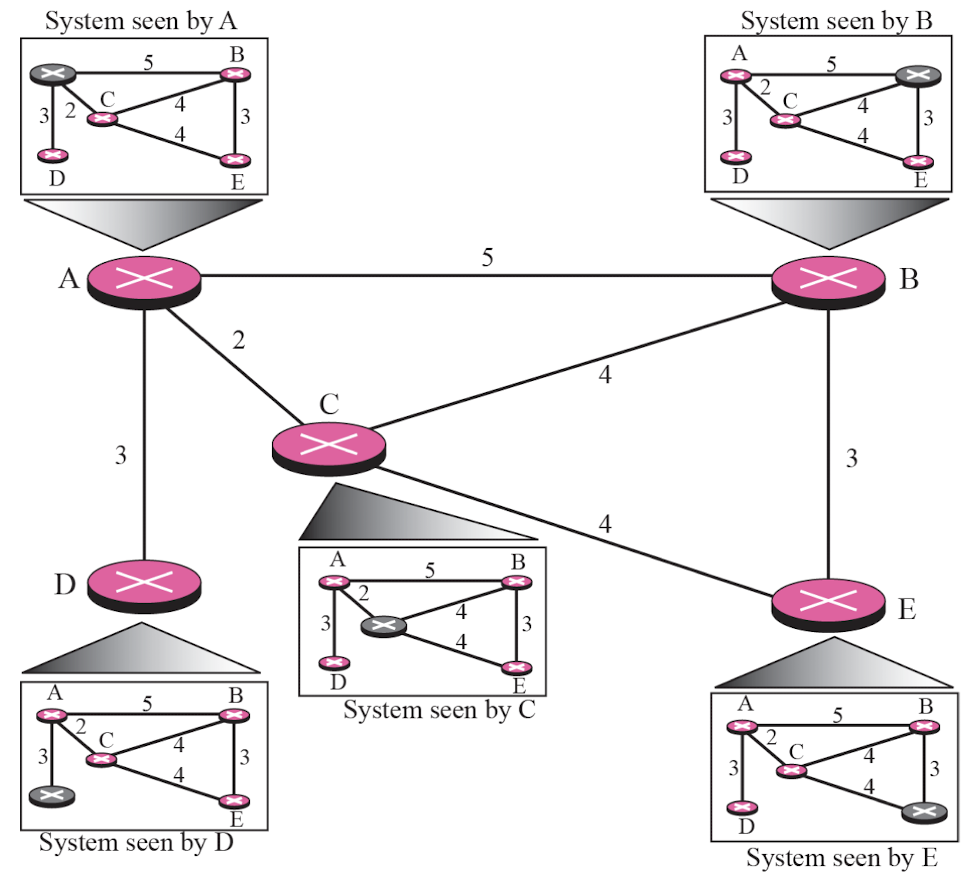
- Link State 라우팅 알고리즘은 네트워크의 토폴로지 정보를 기반으로 최단 경로를 계산하는 방식이다.
- 이 알고리즘은 Dijkstra가 개발한 Shortest Path First(SPF) 알고리즘을 기반으로 한다.
동작 방식
- 네트워크 토폴로지 파악:
- 각 OSPF 라우터는 Hello 패킷을 사용하여 인접 라우터를 발견하고, 링크 상태 정보를 교환한다.
- 링크 상태 정보에는 라우터 ID, 인터페이스 IP 주소, 링크 비용(메트릭) 등이 포함된다.
- 라우터는 수집한 링크 상태 정보를 Link-State Advertisement(LSA)라는 패킷에 담아 네트워크 전체에 플러딩한다.
- Link-State Database(LSDB) 구축:
- 각 라우터는 수신한 LSA를 기반으로 네트워크의 전체 토폴로지 정보를 포함하는 LSDB를 구축한다.
- LSDB는 네트워크의 모든 노드와 링크에 대한 정보를 그래프 형태로 저장한다.
- 모든 라우터는 동일한 LSDB를 유지하므로, 네트워크에 대한 일관된 뷰를 가지게 된다.
Shortest Path First(SPF) 계산:
- 각 라우터는 LSDB를 입력으로 사용하여 SPF 알고리즘을 실행한다.
- SPF 알고리즘은 라우터 자신을 루트로 하는 최단 경로 트리(Shortest Path Tree)를 계산한다.
- 알고리즘은 링크 비용을 기반으로 각 노드까지의 최단 경로를 찾는다.
- 링크 비용은 일반적으로 대역폭, 지연 시간, 신뢰성 등을 고려하여 관리자가 설정한다.
라우팅 테이블 생성:
- SPF 계산 결과로 얻은 최단 경로 트리를 기반으로 라우팅 테이블을 생성한다.
- 라우팅 테이블에는 각 목적지 네트워크에 대한 최적의 경로 정보가 포함된다.
- 경로 정보에는 목적지 네트워크 주소, 넥스트 홉(Next Hop) 라우터, 출력 인터페이스 등이 포함된다.
경로 업데이트 및 수렴:
- 네트워크 토폴로지가 변경되면(링크 추가, 삭제, 비용 변경 등) 해당 라우터는 새로운 LSA를 생성하고 전파한다.
- 모든 라우터는 업데이트된 LSA를 기반으로 LSDB를 갱신하고, SPF 알고리즘을 다시 실행하여 최단 경로를 재계산한다.
- 이 과정을 통해 네트워크 전체의 라우팅 정보가 일관되게 유지되고, 변경 사항에 빠르게 수렴된다.
Link State Routing 예시
- A router의 시점에서 아래와 같은 순서로 최단 비용을 구한다.
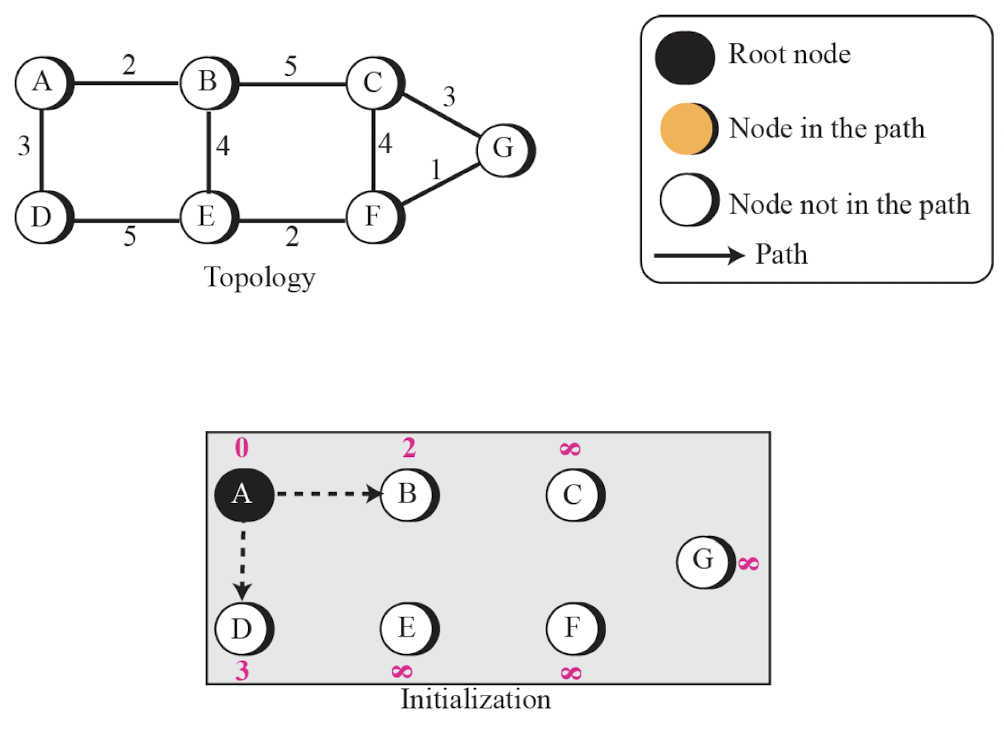
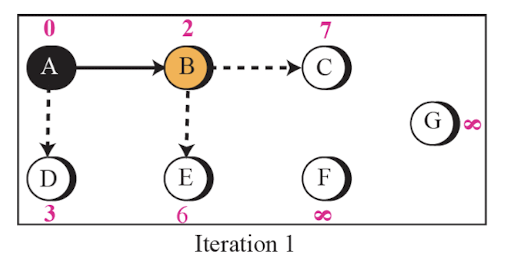
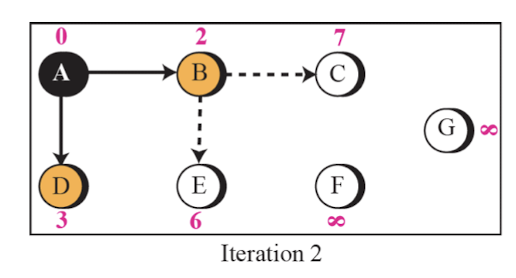
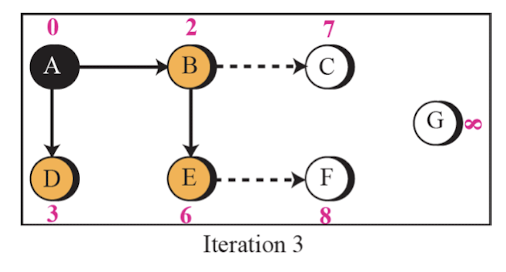
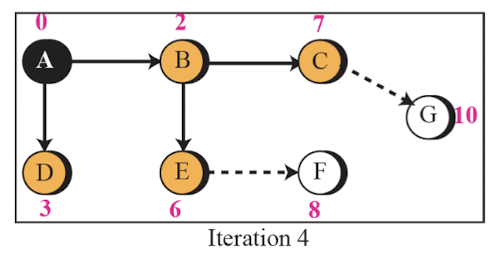
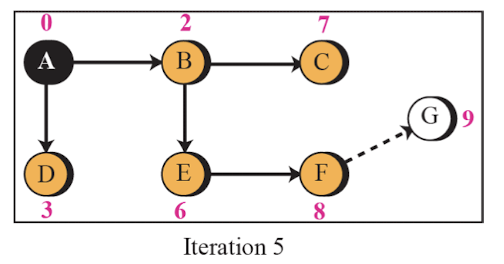
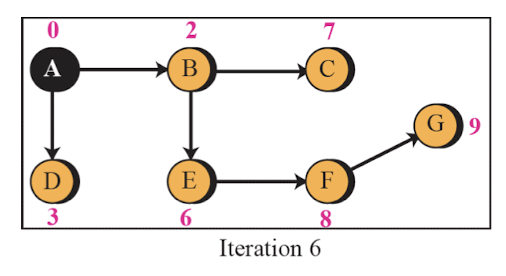
- 이러한 최단 비용은 각 router 마다 구해진다.
Inter-domain Routing Protocol
BGP
- 인터넷 서비스 제공자(ISP) 간의 라우팅 정보 교환을 위해 사용되는 표준 외부 게이트웨이 프로토콜(EGP)이다.
- BGP는 자율 시스템(Autonomous System, AS) 간의 경로 정보를 교환하고, 인터넷의 글로벌 연결성을 유지하는 데 핵심적인 역할을 담당한다.
특징과 동작 원리
- BGP 세션 설정:
- BGP 라우터 간에는 TCP 포트 179를 사용하여 BGP 세션이 설정된다.
- 세션 설정 과정에서 BGP 라우터는 자신의 AS 번호, BGP 버전, 홀드 타임 등의 정보를 교환한다.
- 세션이 설정되면 BGP 라우터 간에 키핑얼라이브(Keepalive) 메시지를 주기적으로 교환하여 세션을 유지한다.
- 경로 정보 교환:
- BGP 라우터는 Update 메시지를 사용하여 경로 정보를 교환합니다.
- Update 메시지에는 목적지 네트워크 주소, AS 경로(AS_PATH), Next_Hop 등의 정보가 포함됩니다.
- AS 경로는 해당 경로가 통과한 AS들의 순서를 나타내는 것으로, BGP의 루프 방지 메커니즘으로 사용된다.
- 경로 선택:
- BGP 라우터는 수신한 경로 정보를 기반으로 최적의 경로를 선택한다.
- 경로 선택 과정에서는 다양한 속성(Attribute)이 고려된다.
- 예를 들어, LOCAL_PREF, MED, AS_PATH 길이 등이 있다.
- 네트워크 관리자는 조직의 라우팅 정책에 따라 이러한 속성을 조정하여 트래픽 흐름을 제어할 수 있다.
정책 기반 라우팅:
- BGP는 유연한 정책 기반 라우팅을 지원한다.
- 라우터는 수신한 경로 정보에 대해 필터링, 우선순위 설정, 속성 변경 등의 정책을 적용할 수 있다.
- 이를 통해 조직 간의 트래픽 제어, 보안 강화, 부하 분산 등을 구현할 수 있다.
- 확장성 및 안정성:
- BGP는 인터넷의 확장성과 안정성을 유지하는 데 중요한 역할을 한다.
- 경로 집계(Route Aggregation) 기능을 통해 라우팅 테이블의 크기를 줄일 수 있다.
- BGP의 점진적 업데이트 메커니즘은 네트워크 변경 사항이 전체 인터넷에 미치는 영향을 최소화한다.
- BGP 세션 설정:
- IBGP와 EBGP:
- BGP는 AS 내부에서 사용되는 IBGP(Internal BGP)와 AS 간 사용되는 EBGP(External BGP)로 구분된다다.
- IBGP는 AS 내의 BGP 라우터 간에 경로 정보를 교환하고 동기화하는 데 사용된다.
- EBGP는 서로 다른 AS에 속한 BGP 라우터 간에 경로 정보를 교환하는 데 사용된다.
Path Vector Routing
- Distance Vector 라우팅의 한 종류로, 경로 정보를 전파할 때 경로에 포함된 모든 노드(라우터)의 정보를 함께 전달하는 방식이다.
대표적인 Path Vector 라우팅 프로토콜로는 BGP(Border Gateway Protocol)가 있다.
주요 동작과 특징
경로 정보의 구성:
- Path Vector 라우팅에서 경로 정보는 목적지 네트워크 주소, 해당 경로의 총 비용(메트릭), 그리고 경로상의 모든 노드(라우터) 목록으로 구성된다.
- 노드 목록은 경로 벡터(Path Vector)라고 하며, 목적지까지의 경로에 포함된 라우터들의 식별자(예: IP 주소)를 순서대로 나열한 것이다.
경로 정보의 교환:
- 라우터는 인접한 라우터들과 경로 정보를 교환합니다.
- 경로 정보를 수신한 라우터는 수신된 경로 벡터에 자신의 식별자를 추가하고, 인접 라우터들에게 이를 전파한다.
- 이 과정을 통해 네트워크 전체의 경로 정보가 점진적으로 전파되고 수렴된다.
루프 방지:
- Path Vector 라우팅은 경로 벡터에 포함된 노드 목록을 사용하여 루프를 방지합니다.
- 라우터는 수신된 경로 정보의 경로 벡터에 자신의 식별자가 이미 포함되어 있는지 확인합니다.
- 만약 자신의 식별자가 경로 벡터에 존재한다면, 이는 루프가 발생한 것으로 판단하고 해당 경로를 폐기한다.
정책 기반 라우팅:
- Path Vector 라우팅은 경로 선택 시 다양한 정책을 적용할 수 있다.
- 라우터는 경로 벡터에 포함된 노드 정보를 기반으로 경로 필터링, 우선순위 설정, 속성 변경 등의 정책을 적용할 수 있다.
- 이를 통해 네트워크 관리자는 트래픽 흐름을 세밀하게 제어하고, 조직 간 라우팅 정책을 구현할 수 있다.
- 확장성:
- Path Vector 라우팅은 대규모 네트워크에서도 효율적으로 동작할 수 있다.
- 경로 벡터에 포함된 노드 정보를 기반으로 경로 집계(Route Aggregation)를 수행할 수 있어, 라우팅 테이블의 크기를 줄일 수 있다.
- 또한, 계층적 구조를 통해 라우팅 도메인을 분리하고, 도메인 간 경로 정보 교환을 최소화할 수 있다.
This post is licensed under CC BY 4.0 by the author.