Computer-Architecture 2. Instructions - Language of the computer
컴퓨터 구조 공부 기록
Computer-Architecture 2. Instructions - Language of the computer
Instruction Set(명령어 집합)
- RISC(Reduced Instruction Set Computer)
- 복잡한 명령어 대신 적은 수의 간단한 명령어를 사용한다. 이를 통해 각 명령어를 하드웨어로 매우 효율적으로 구현할 수 있다.
- 레지스터 사용 RISC는 메모리 접근 대신 레지스터를 많이 활용하여 데이터 전달을 신속하게 한다.
- 파이프라이닝(Pipelining) 명령어 실행을 여러 단계로 나누어 동시에 진행하는 파이프라이닝 기법을 적극 활용한다.
- 고정 길이 명령어 모든 명령어가 동일한 비트 길이를 가지므로 디코딩이 쉽다.
- 주로 모바일 기기와 임베디드 시스팀에서 주로 사용된다
- ex : MIPS(32-bit), ARMv7(32-bit), ARMv8(64-bit)
- CISC(Complex Instruction Set Computer)
- 수천 개의 다양한 명령어를 가지고 있다. 이를 통해 하나의 명령어로 복잡한 작업을 처리할 수 있다.
- Memory to Memory access CISC는 메모리에 직접 접근하여 데이터를 처리할 수 있다.
- 레지스터 대신 메모리를 많이 활용한다.
- 가변 길이 명령어 명령어의 비트 길이가 가변적이어서 디코딩이 복잡하다.
- 복잡한 명령어를 처리하기 위해 마이크로코드를 사용하여 간접적으로 실행한다.
Arithmetic Operation
- 산술 연산은 2개의 source와 1개의 destination 으로 이루어졌다.
1 2
add a, b, c # a gets b + c sub a, b, c # a gets b - c
- Design principle 1 : 간단한 것을 위해선 규칙적인 것이 좋다.
- ex
1
2
3
4
5
6
7
C code :
f = (g + h) - (i + j);
Compiled MIPS code:
add t0, g, h # temp t0 = g + h
add t1, i, j # temp t1 = i + j
sub f, t0, t1 # temp f = t0 - t1
MIPS의 register
- MIPS는 32bit의 레지스터 32개가 존재(32개 이상은 메모리에 저장)
- $t0 ~ $t9 : 임시 변수 전용 레지스터
- $s0 ~ $s7 : 변수로 선언된 값들을 저장하기 위한 레지스터
- Design Principle 2 : 작은 것이 더 빠르다
Memory Operand
- lw $t0, 8($s1) : Load values from memory into $t0 (Load Word)
- $t0 : 레지스터(대상), 8($s1) : 표현식 1개(메모리주소, $s1 + 8)
- sw $t0, 8($s1) : Store result from $t0 to memory (Store Word)
- 메모리는 8bit씩 나눠서 주소를 매김
- 레지스터의 크기는 32bit이므로 4개의 주소를 한꺼번에 쓴다.(때문에 주소는 4의 배수)
- MIPS는 Big Endian 이므로 큰 주소가 끝에 온다.
1
2
3
4
5
6
C code:
g = h + A[8];
Compiled MIPS code:
lw \$t0, 32(\$s3) #load word
add \$s1, \$s2, \$t0
- MIPS는 메모리에서 가져오는 것과 연산하는 것이 구분되게 동작한다(연산자의 clock 수가 일정하게 되기 위해)
Immediate Operand
- 상수 연산은 Load가 필요 없다.
1
addi \$s3, \$s3, 4
- 빼기(sub) 연산자가 없다(음수를 더하는 식으로 동작)
1
addi \$s3, \$s3, -4
Design principle 3 : 자주 생기는 일을 빠르게 하라
Zero Register : $Zero 는 0을 지정해놓은 레지스터
2의 보수법
- 어떤 수의 -(음수)는 각 bit의 보수 + 1이다.
- 단, -2^(n-1)은 똑같다.(음의 최댓값은 보수를 취하고 더해줘도 똑같다.)
- Sign Extension은 첫 번째 비트로 확장한다.
MIPS의 Instruction 표현
- Instruction을 32bit 크기로 맞춰둠
- R - format Instruction

- op(opcode) : 명령에 의해 수행될 작업 지정, R-format의 경우 항상 0으로 설정
- rs : 첫 번째 소스 레지스터 피연산자를 지정. 즉, 첫번째 피연자를 읽을 레지스터
- rt : 두 번째 소스 레지스터 피연산자를 지정. 즉, 두 번째 피연산자를 읽을 레지스터
- rd : 연산 결과가 기록될 레지스터
- shamt : shift 명령에 의한 shift 양을 지정하는 필드
- funct : 명령어가 수행할 작업을 추가로 지정하는 필드
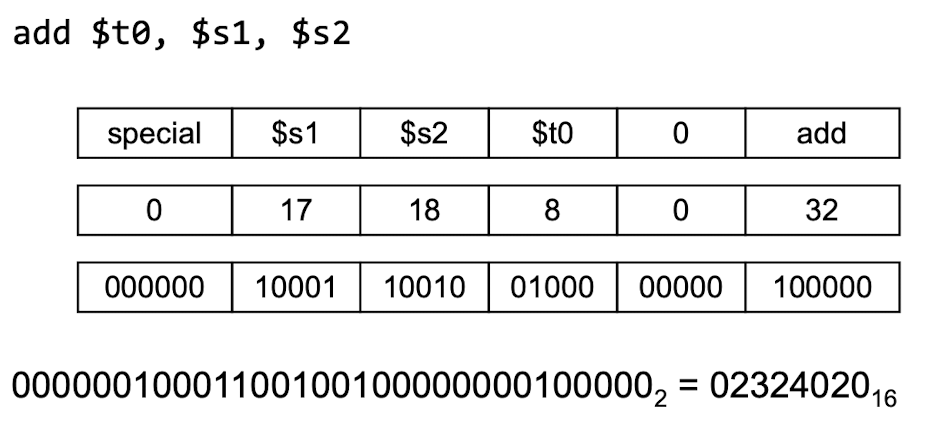
- I - format Instruction

- rt : destination 역할 또는 source register
- rs : source register
- constant or address : 상수나 메모리주소(이와 같은 이유로 상수는 -2^15 ~ 2^15 - 1까지 밖에 표현하지 못함)
- Design principle 4 : 좋은 설계에는 적당한 절충이 필요
Logical Operation
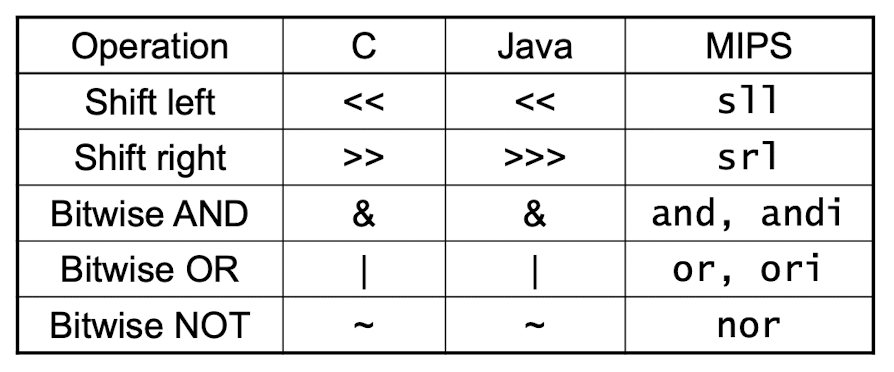
NOT Operation
- NOT이 없고 NOR를 활용해 NOT을 표현
- a nor 0 == NOT
Conditional Operations
- Branch to a labeld instruction if a condition is true
- Otherwise, continue sequentially
- beq rs, rt, L1 == if(rs == rt) 이면 L1으로 가라
- bne rs, rt, L1 == if(rs != rt) 이면 L1으로 가라
j L1 : 그냥 L1으로 가라
- Basic Block :
More Conditional Operation
- slt rd, rs, rt : if (rs < rt)이면 rd = 1, 아니면 rd = 0
- slt rd, rs, 상수 : if (rs < 상수)이면 rd = 1, 아니면 rd = 0
- blt, bge 같은 것이 없는 이유 : clock이 1 clock 이상 소모되므로, clock period를 맞추기 위해 clock period를 늘려 다른 Instruction이 전체적으로 느려지는 현상이 생긴다.
Procedure Calling
- 레지스터 값을 저장하는 과정
- 반환 주소 저장 : $sa(반환 주소)레지스터에 프로시저를 호출한 jal(점프 및 이동) 명령 바로 다음 명령의 주소가 저장(jal 명령에 의해 실행되는 동작)
- 현재 스택 포인터 저장 : 스택 포인터($sp)의 현재 저장 값은 프로시저의 지역 변수를 위한 공간을 만들기 위해 스택 포인터가 조정되기 전에 $fp(프레임) 포인터와 같은 지정된 레지스터에 저장된다.
- 호출된 프로시저에서 사용할 레지스터를 저장. 작업을 수행하기 위해 호출된 프로시저에서 사용할 레지스터는 내용을 덮어쓰지 않게 저장. 레지스터의 내용을 스택에 복사
- 스택 포인터 조정
- 호출된 프로시저로 전송
- jal ProcedureLabel : 돌아올 곳을 $sa에 저장 후 이동
- jr $ra : $ra에 있는 주소로 리턴
함수 호출에 쓰이는 레지스터
- $a0 – $a3: arguments (reg’s 4 – 7) (caller가 저장, 매개 변수 전달용)
- $v0, $v1: result values (reg’s 2 and 3)
- $t0 – $t9: temporaries (caller가 저장해야 됨)
- Can be overwritten by callee
- $s0 – $s7: saved (callee가 저장해야 함)
- Must be saved/restored by callee
- $gp: global pointer for static data (reg 28)
- $sp: stack pointer (reg 29) (지역 변수 저장, 매개 변수 4개 이상일 경우 stack에 저장)
- $fp: frame pointer (reg 30) (사용할 stack의 시작 주소를 가리키고, 상대 주소를 사용)
- $ra: return address (reg 31) (함수를 끝내고 돌아올 주소)
Leaf Procedure(다른 함수를 호출하지 않는 말단 함수)
- 예시 코드
int leaf_example(int g, h, i, j)
{
int f;
f = (g + h) - (i + j);
return f;
}
- MIPS code

Non-Leaf Procedure
- 예시 코드
int fact(int n)
{
if(n < 1) return 1;
else return n * fact(n-1);
}
MIPS 코드
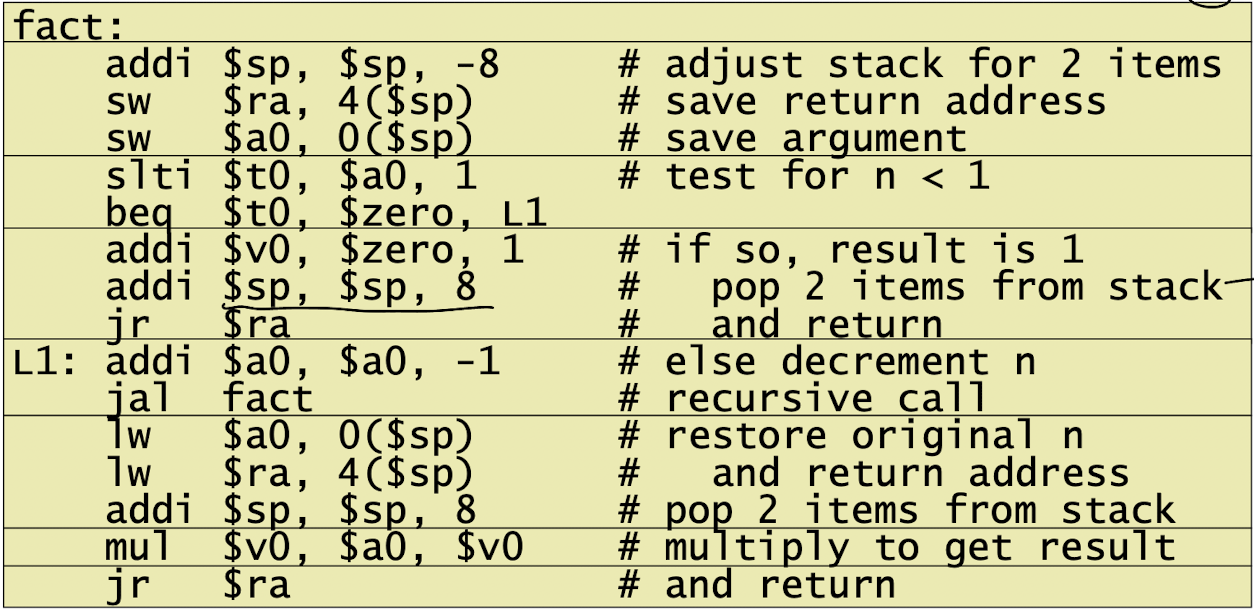
말단 함수와 달리 return address를 저장하는 것을 볼 수 있다
Local Data on the Stack
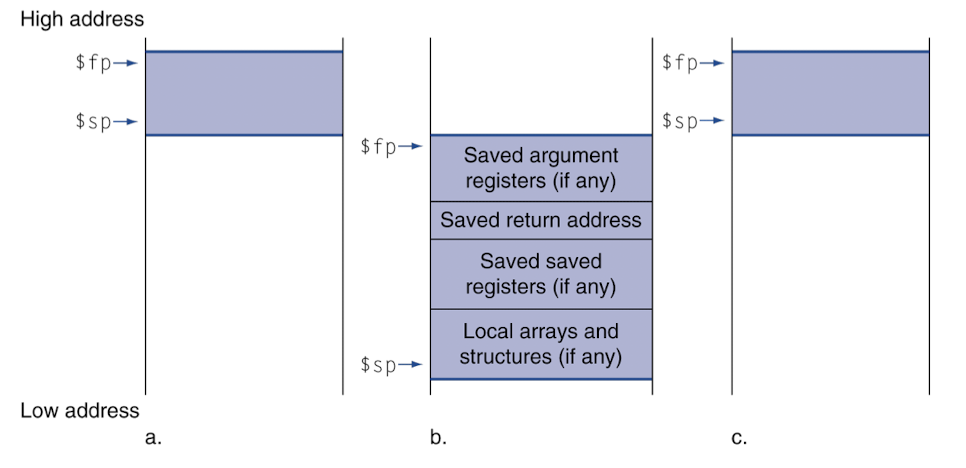
- 스택의 시작점을 두고 상대주소를 활용하는 것을 볼 수 있다.
- $fp : Frame Pointer
- $sp : Stack Pointer
Memory Layout
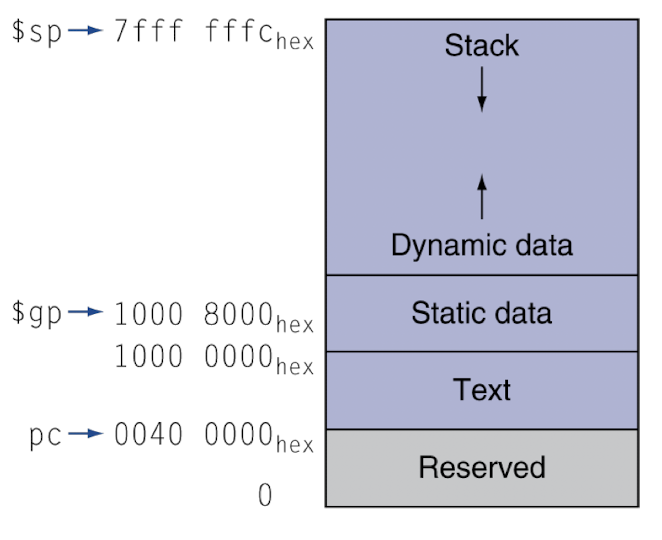
- Text (Code) Segment:
- 프로그램의 실행 가능한 명령어들이 포함되어 있다.
- 이 segment는 일반적으로 읽기 전용(read-only)으로 설정되어 프로그램 코드의 우발적인 수정을 방지한다.
- Text segment의 크기는 프로그램 실행 내내 고정되어 있다.
- 프로그램의 실행 가능한 명령어들이 포함되어 있다.
- Data Segment:
- 프로그래머가 초기화한 전역 변수와 정적 변수가 된다.
- Data segment의 변수들은 고정된 크기를 가지며 프로그램의 생명 주기 동안 존재한다.
- Data segment는 두 부분으로 나뉜다:
- Initialized Data: 프로그래머가 명시적으로 초기화한 변수들이 포함된다.
- Uninitialized Data (BSS): 명시적으로 초기화되지 않은 변수들이 포함되며, 시스템에 의해 자동으로 0으로 초기화된다.
- 상수의 표현 범위가 0000 ~ FFFF인데 static data의 시작 주소는 이미 1000 0000 이므로 범위를 벗어나고 시작이다
- 때문에 static data의 중간 부분에 $gp를 심어놓는다. 그러면 해당 $gp에서 덧셈, 뺄셈 연산을 통해 정상적으로 원하는 메모리 주소에 접근할 수 있다.
- Heap:
- 프로그램 실행 중에 동적 메모리 할당에 사용된다.
- C에서는 malloc(), calloc(), realloc(), free() 등의 함수를 사용하여 메모리를 할당하고 해제한다.
- Heap은 프로그램의 메모리 요구 사항에 따라 동적으로 증가하거나 감소한다.
- Heap은 운영 체제의 메모리 관리 시스템에 의해 관리된다.
- Stack:
- 지역 변수, 함수 매개변수, 반환 주소 등을 저장하는 데 사용된다.
- 함수가 호출되고 반환될 때 Stack은 증가하거나 감소한다.
- 각 함수 호출은 지역 변수와 기타 관련 정보를 포함하는 새로운 Stack Frame을 생성한다.
- Stack은 Last-In-First-Out (LIFO) 구조를 따르며, 가장 최근에 push된 항목이 먼저 액세스된다.
- Command Line Arguments and Environment Variables:
- 프로그램 실행 시 전달된 명령줄 인수가 포함되어 있다.
- 프로그램에서 접근할 수 있는 환경 변수도 포함된다.
- Shared Libraries:
- 런타임에 프로그램에 링크되는 공유 라이브러리(동적 라이브러리)의 코드와 데이터가 포함되어 있다.
- 공유 라이브러리는 프로그램 시작 시 또는 처음 접근할 때 메모리에 로드된다.
- 여러 프로그램이 공통 기능을 공유할 수 있도록 하여 코드 재사용과 모듈식 설계를 가능하게 한다.
- Kernel Space:
- 운영 체제의 커널과 그 데이터 구조를 위해 예약되어 있다.
- 사용자 프로그램은 일반적으로 Kernel Space에 직접 접근할 수 없다.
Byte/Halfword(2byte) Operation
- MIPS의 byte/halfword load/store
- lb rt, offset(rs) lh rt, offset(rs)
sb rt, offset(rs) sh rt, offset(rs)
- b : 제약 사항
- h : 2의 배수가 되어야 함
- w : 4의 배수가 되어야 함
- 예시

32-bit constant
- lui $rt, constant1 : 레지스터의 상위 16bit에 상수 값을 넣어줌
- ori $s0, $s0, constant2 : 하위 16bit에 or 연산을 이용해 하위 값을 넣어줌
- ex

- $s0 = 61 * 2^16 + 2304
Branch Addressing
- beq, bne는 I-format을 따른다.
- constant or address section은 0000~FFFF가 jump할 수 있는 구간(너무 작다)
- 때문에 branch는 address를 실제로 계산할 때 PC(현재 코드 위치)의 위, 아래에 있다고 가정하고 relative-addressing(즉, PC의 상대 주소로 계산)한다.
- 그러므로 Target address(실제 Jump 도착지) = PC + offset * 4가 된다.
- 여기서 곱하기 4가 들어가는 이유는 4byte씩 align되기 때문에 앞의 00이 생략됐기 때문이다.
- 또한 실제로는 PC가 이미 증가하였기 때문에 PC + 4 + offset * 4가 된다.
- 즉, branch의 Jump 범위는 PC+4-2^17 ~ PC+2^17이다.
Jump Addressing

- 26bit으로 표현할 수 있기 때문에 절대 주소처럼 표현한다.
- 하지만 이또한 앞에 00이 생략 되어 있는 것이기 때문에 28bit을 표현할 수 있는 것과 마찬가지이다.
Target Addressing Example

- 80012의 address 부분에 2가 들어간 이유 :
- Exit으로 Jump하기 위해 PC + 12를 해야하기 때문에 PC + 4 + offset * 4 = PC + 12가 되어야함
- 때문에 offset = 2가 됨.
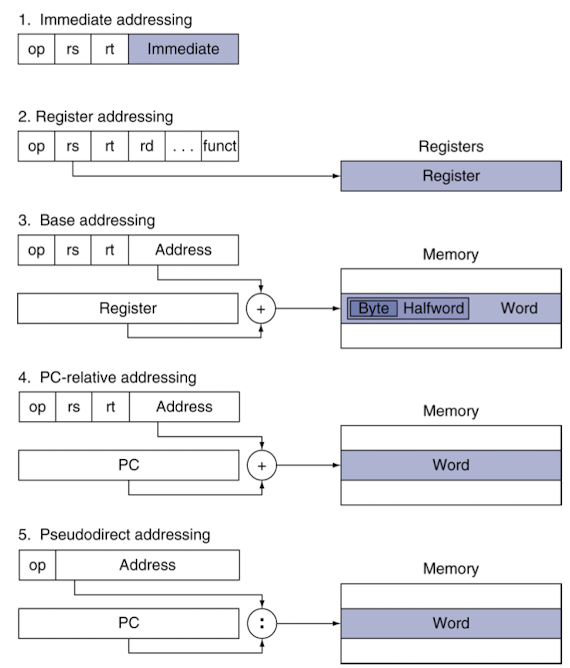
Address Mode Summary
Synchronization
- 프로세스들이 공유자원에 대한 접근하였을 때 순서를 지정해주는 것
- Atomic read/write operation이 필요하다.
- ex : atomic swap
- Load linked : ll rt, offset(rs) -> rt에 offset(rs)의 값을 sc 명령어와 링크 후 읽어옴
- Store conditional : sc rt, offset(rs) -> 조건에 따라 실패할 수 있는 store
- 조건 : offset(rs)에 다른 프로세서, 혹은 스레드가 write을 시도했으면 store 실패
- 성공 시 : offset(rs)에 rt 값을 저장 후 rt에 1저장
- 실패 시 : store 실패, rt에 0을 저장
Assembler Pseudo-instructions
- 어셈블러 레벨에서는 없는 Instruction들도 일ㄷ단 그래도 쓰고, 기계어로 변환할 때 바꿔줌(이때 $at같은 임시 레지스터를 추가로 사용함)
- 사람이 잘 이해할 수 있게 하기 위함.
Producing an object model
- Assembler : Assemble 언어의 프로그램을 기계어로 바꾸는 역할
- 기계어로 번역된 뒤에 실제 파일에는 몇가지 정보가 더 저장되어 있다.
- Header : 각 파일들의 영역으로 나타내고, 사이즈나 위치를 알려줌
- Text segment : 기계어(code)
- Static data segment : 전역 변수들 저장
- Relocation info : 재배치에 사용할 정보들 저장
- Symbol table : 선언과 정의가 나뉜 값들
- Debug info : 원래 코드에 어떤 부분들인지, 어떻게 엮여있는지 디버깅에 활용할 데이터 저장
Linking object Modules
- 컴파일러나 어셈블러에 의해 생성된 객체 모듈들을 하나의 실행 가능한 프로그램으로 결합하는 과정이다.
- Linker가 해당 작업을 수행
- 영역별로 합침
- Label들의 실제 주소 결정
- 파일 밖에 헤더 파일 같은걸 가져옴
Loading a Program
- 실행 파일을 메모리에 적재하는 과정
- Loader가 해당 작업을 수행
- 메모리 공간 확보
- create virtual address space
- 메모리에 있는 데이터를 초기화하고 code를 복사
- stack에 argument들을 세팅
- 레지스터들 초기화
- main 함수 argument들을 넣어서 첫줄 실행
Dynamic Linking
- 프로그램 실행 중에 필요한 라이브러리를 동적으로 로드하고 링크하는 기술이다.
- 공유 라이브러리(Shared Library) 또는 동적 링크 라이브러리(Dynamic Link Library, DLL)라고 불린다.
- 동적 링킹을 사용하면 라이브러리 코드를 여러 프로그램이 공유할 수 있어 메모리 사용량을 줄일 수 있다.
- 라이브러리 업데이트 시 실행 파일을 다시 컴파일하지 않아도 되므로 유지보수에 유리하다.
- 동적 링커(Dynamic Linker)가 프로그램 실행 중에 라이브러리를 로드하고 심볼을 해석하는 역할을 한다.
Lazy linking
- 동적 링킹의 한 형태로, 실제로 함수나 데이터가 사용되는 시점까지 링킹을 지연시키는 기법이다.
- 프로그램 시작 시 모든 심볼을 링크하는 대신, 해당 심볼이 처음 참조될 때 링크가 이루어진다.
- 이를 통해 프로그램의 시작 시간을 단축시키고, 사용되지 않는 코드의 로딩을 피할 수 있다.
- 지연 링킹은 운영체제나 동적 링커에 의해 자동으로 처리된다.
- 함수의 첫 호출 시 발생하는 페이지 폴트(Page Fault)를 트리거로 지연 링킹이 수행된다.
Java의 Application 실행 과정
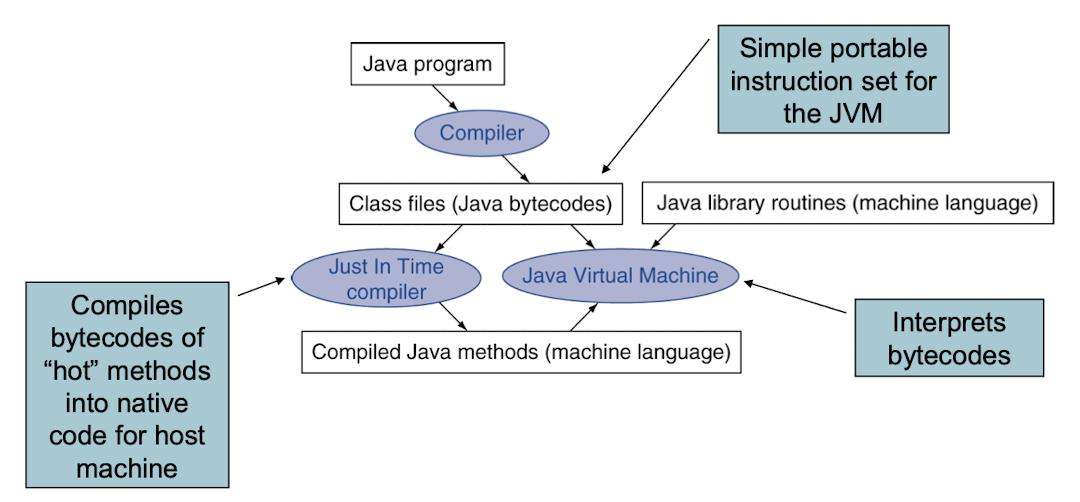
- Java는 호환성을 중요 시 하기 때문에 기계어로 바로 번역하는 것이 아닌 Java의 byte code로 컴파일을 먼저 진행한다.
- 보안성 측면에서 좋다. 하지만 성능은 저하된다.
- 그 이후 JVM이 해독하여 해당 머신에 맞는 기계어로 번역한다.
Effect of Compiler Optimization
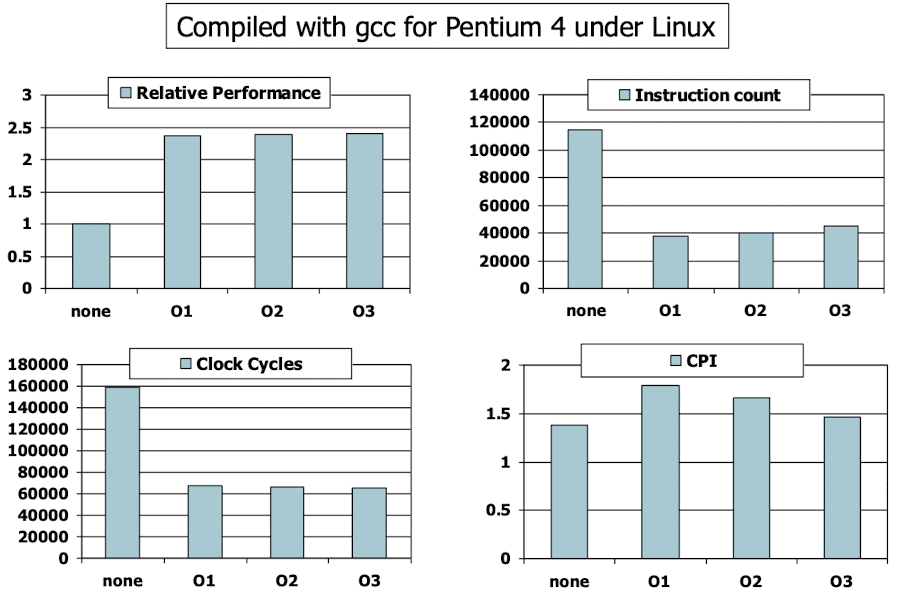
- Instruction count와 CPI는 성능의 좋은 지표가 아니라는 것을 알 수 있다.
- Compiler의 최적화는 알고리즘에 민감하게 반응한다.
Array vs Pointer
직접 메모리 접근
- 포인터는 메모리 주소를 직접 가리키는 변수이다.
- 포인터를 통해 메모리에 직접 접근함으로써 중간 단계를 거치지 않고 빠른 읽기/쓰기 연산이 가능하다.
- 배열의 경우, 인덱스를 사용하여 간접적으로 메모리에 접근하므로 포인터보다 느릴 수 있다.
캐시 효율성
- 프로세서는 자주 접근되는 메모리 영역을 캐시에 저장하여 빠른 접근을 제공한다.
- 포인터를 사용하여 순차적으로 메모리에 접근하면 캐시 적중률(Cache Hit Rate)이 높아져 성능이 향상된다.
- 배열 인덱스를 사용하여 무작위로 메모리에 접근하면 캐시 미스(Cache Miss)가 발생할 확률이 높아진다.
컴파일러 최적화
- 컴파일러는 포인터를 사용한 코드에 대해 더 효과적인 최적화를 적용할 수 있다.
- 포인터 연산은 컴파일 타임에 결정되므로 컴파일러가 최적의 어셈블리 코드를 생성할 수 있다.
- 배열 인덱스를 사용한 코드는 런타임에 계산되므로 컴파일러의 최적화 기회가 제한적일 수 있다.
동적 메모리 할당
- 포인터를 사용하면 동적으로 메모리를 할당하고 해제할 수 있다.
- 필요한 만큼의 메모리를 런타임에 할당함으로써 메모리 사용량을 최소화할 수 있다.
- 배열은 컴파일 타임에 크기가 고정되므로 메모리 낭비가 발생할 수 있다.
- 유연성과 재사용성
- 포인터를 사용하면 함수 간에 메모리 블록을 공유하고 전달할 수 있다.
- 포인터를 매개변수로 사용하여 다양한 자료구조와 알고리즘을 구현할 수 있다.
- 배열은 함수 간 전달 시 크기 정보가 손실될 수 있어 유연성이 제한적이다.
- 실수하기 쉬운 지식
- address + 1은 word size만큼 증가하는 것이다.
- ex : word size가 32bit이면 4byte인 4가 증가한다.
- function 내부에서 생성한 주소가 stack에서 pop되면 없어진 값이 된다.
- address + 1은 word size만큼 증가하는 것이다.
This post is licensed under CC BY 4.0 by the author.