AWS SAA chapter 7. AWS RDS + Aurora + ElastiCache
SAA 자격증 공부 기록
AWS SAA chapter 7. AWS RDS + Aurora + ElastiCache
Amazon RDS 설명
- RDS(Relational Database Service)
- SQL을 쿼리 언어로 사용하는 데이터베이스용 서비스이다.
- 클라우드에 DB를 생성할 수 있고 AWS가 DB를 관리하므로 누릴 수 있는 혜택이 많다.
- AWS가 관리하는 DB엔진의 유형
- PostgreSQL
- MySQL
- MariaDB
- Microsoft SQL Server
- Oracle
- Aurora(AWS Proprietary database)
DB 인스턴스 클래스
- Standard
- 메모리 최적화
- 버스트 가능 성능
- 기준치 이하의 cpu 사용량일 경우 credit을 채우다가 cpu 사용량이 기준치를 넘어 설 때 credit을 사용하여 이에 대응하는 방식
Advantage over using RDS vs Deploying DB on EC2
- EC2 인스턴스에 자체 DB 서비스를 배포하지 않고 RDS를 사용하는 이유는 안쓸 이유가 없기 때문이다.
- RDS는 managed service이다
- 데이터베이스 프로비저닝과 기본 운영체제 패치가 완전 자동화 되어 있다.
- 지속적으로 백업이 생성되므로 특정 타임스탬프. 즉, 특정 시점으로 복원할 수도 있다.
- 데이터베이스의 성능을 대시보드에서 모니터링할 수 있다.
- 읽기 전용 복제본을 활용해 읽기 성능을 개선할 수 있다.
- 재해 복구 목적으로 다중 AZ를 설정할 수 있다.
- 유지 관리 기간에 업그레이드 할 수 있다.
- 수직 확장하거나 읽기 전용 복제본을 추가하여 수평 확장할 수 있다.
- 파일 스토리지는 EBS에 구성된다.(gp2, io1)
- 한 가지 단점은 RDS 인스턴스에 SSH 액세스를 할 수 없다.
RDS - Storage Auto Scaling
- 데이터 베이스 용량이 시간이 지남에 따라 부족해질 경우 RDS 스토리지 오토 스케일링 기능이 활성화되어 있으면 RDS가 이를 감지해서 자동으로 스토리지를 확장해준다.
- 스토리지 용량을 늘리기 위해 DB를 다운시키는 등의 작업을 할 필요가 없다.(수동으로 확장하는 작업을 피할 수 있다)
- Maximum Storage Threshold(최대 스토리지 임곗값)을 설정하여 스토리지를 확장할 최대치를 정한다.
- 할당된 용량에서 남은 공간이 일정 비율 미만이되면 스토리지를 자동으로 수정한다.
- 스토리지 부족 상태가 5분 이상 지속되거나 지난 수정으로부터 6시간이 지났을 경우에 오토 스케일링이 활성화되어 있다면 스토리지가 자동으로 확장된다.
- 워크로드를 예측할 수 없는 애플리케이션에서 굉장히 유용하다.(모든 RDS 데이터베이스 엔진에서 지원되는 기능이다)
RDS Read Replicas for read scalability
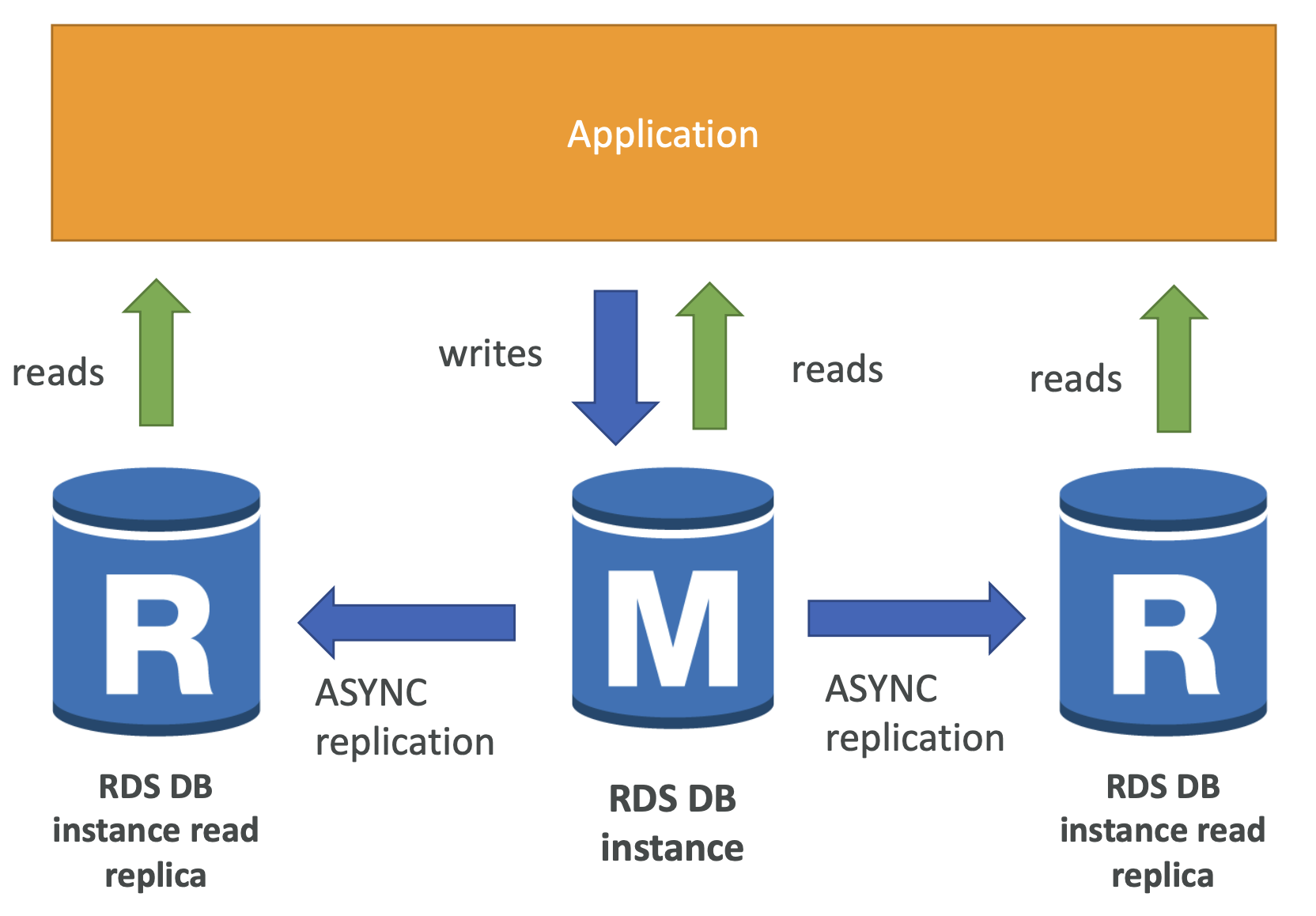
- 읽기 전용 복제본은 이름에서 알 수 있듯 읽기를 스케일링한다.
- 애플리케이션은 데이터베이스 인스턴스에 대해 읽기와 쓰기를 수행한다. 하지만 main 데이터베이스 인스턴스가 너무 많은 요청을 받아서 충분한 스케일링를 할 수 없을 때 read scalability 를 할 수 있다.
- 이때 읽기 전용 복제본을 최대 15개까지 생성할 수 있으며
- 이들은 동일한 가용 영역 또는 가용영역이나 리전에 걸쳐 생성될 수 있다.
- 복제가 될 때 main RDS 데이터베이스 인스턴스와 읽기 전용 복제본 사이에 비동기식 복제가 발생한다.
- 이러한 복제본이 읽기 스케일링 이외에도 데이터베이스로 승격시켜 이용할 수 있다. 자체적인 생애 주기를 갖게 된다.
- 읽기 전용 복제본을 사용하려는 경우에는 애플리케이션에 있는 모든 연결을 업데이트해야 한다.
RDS Read Replicas - Use Cases
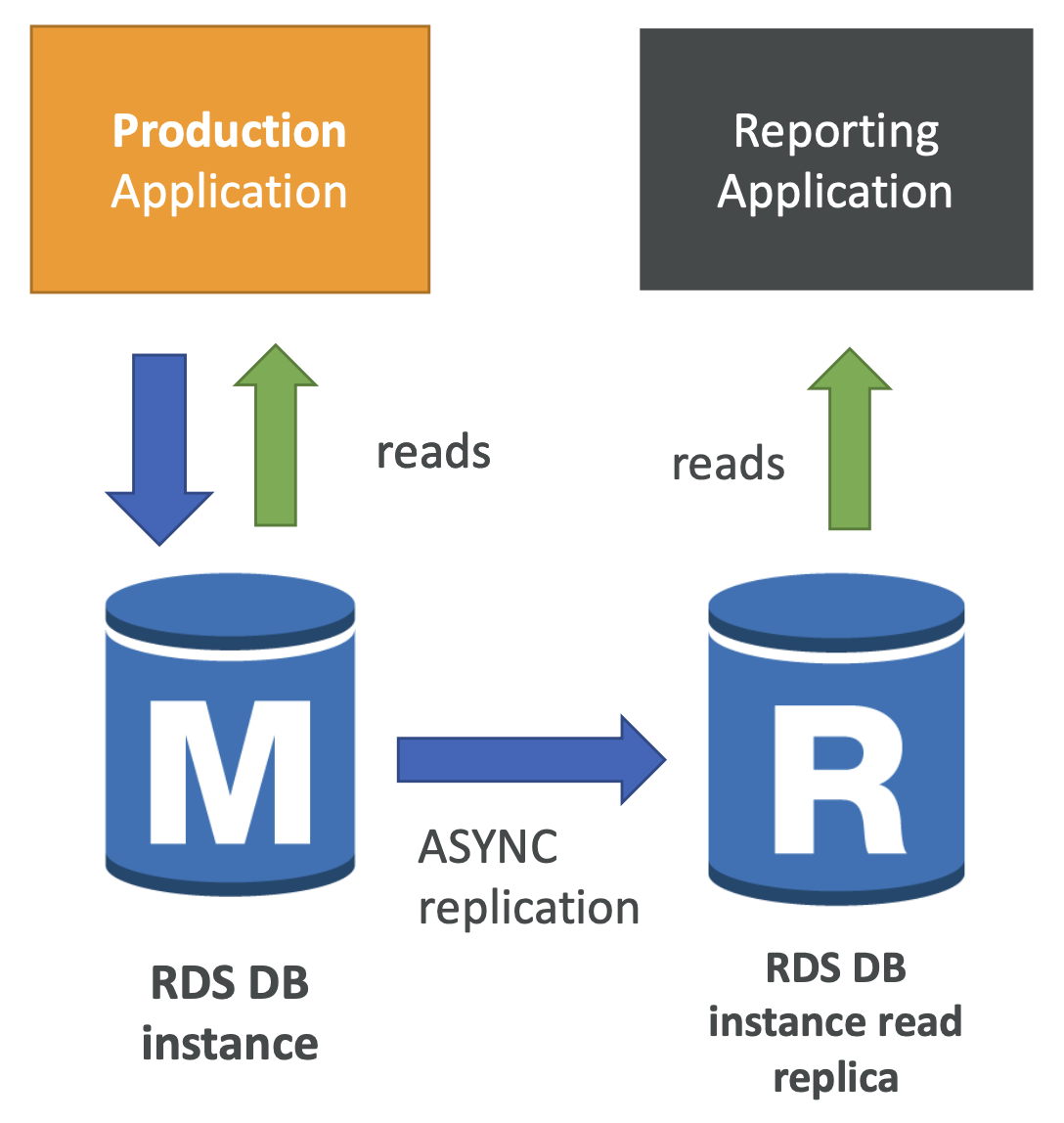
- 평균적인 load를 감당하고 있는 프로덕션 데이터베이스가 있을 때
- 데이터 베이스에서는 읽기와 쓰기가 수행된다.
- 새로운 팀이 와서 데이터를 기반으로 몇가지 보고와 분석을 실시한다고 할 때, report 애플리케이션을 main RDS 데이터베이스 인스턴스에 연결하면 오버로드가 발생하고 생산 애플리케이션의 속도가 느려지게 된다.
- 이때 새로운 워크로드에 대한 읽기 전용 복제본을 생성하는 것이다.
- 이를 통해 보고 애플리케이션이 생성한 읽기 전용 복제본에서 읽기 작업과 분석을 실행할 수 있게 되는 것이다.
- 기존 main 애플리케이션은 이러한 과정에서 성능의 영향을 받지 않기 때문에 이상적인 결과이다.
RDS Read Replicas - Network Cost
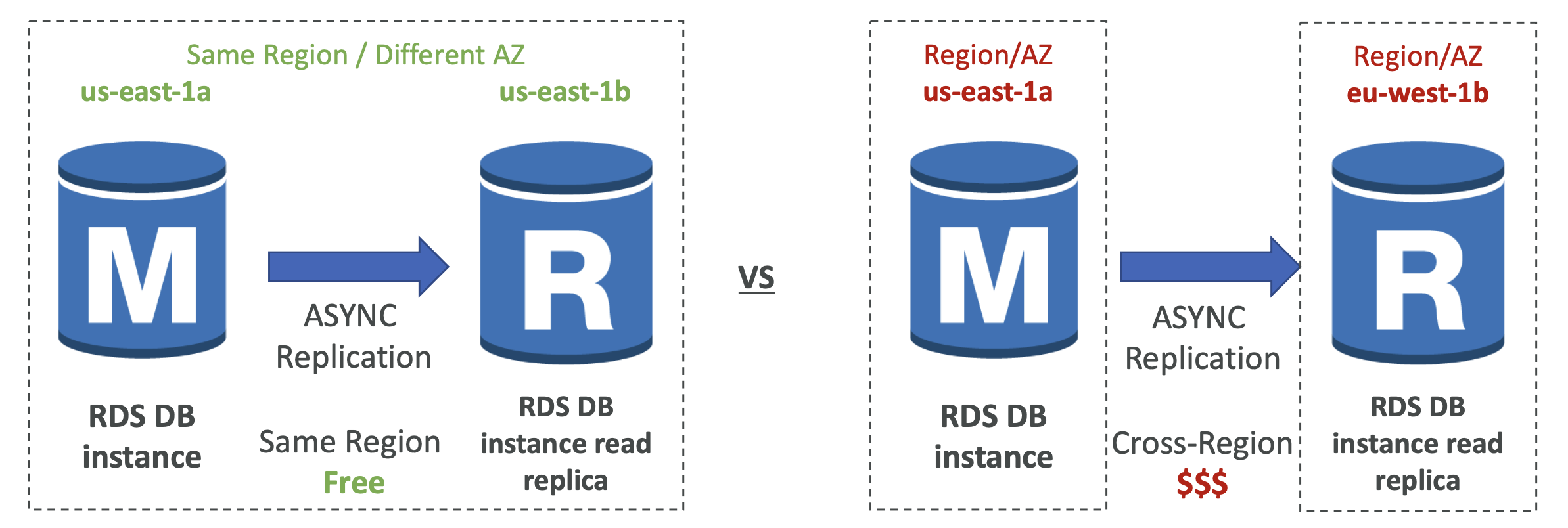
- AWS에서는 하나의 가용 영역에서 다른 가용 영역으로 데이터가 이동할 때 비용이 발생하지만, 읽기 전용 복제본이 다른 AZ 상이지만 동일한 리전 내에 있을 때는 비용이 발생하지 않는다.
- 하지만 서로 다른 리전에 복제본이 존재하는 경우 비용이 발생한다.
RDS Multi AZ(Disaster Recovery)
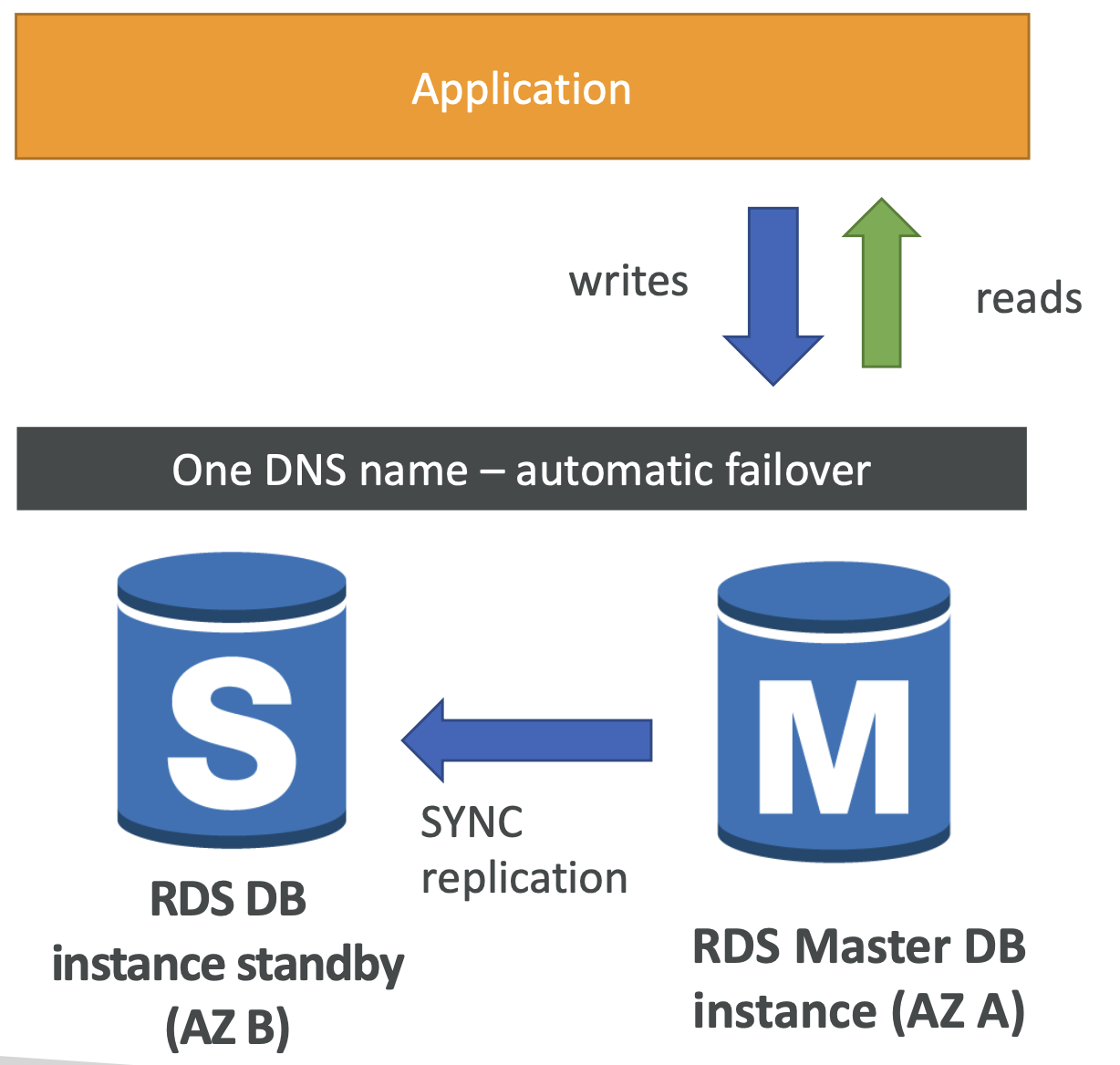
- 다중 AZ 간에 마스터 데이터베이스의 모든 변화를 동기적으로 StandBy(대기) instance에 복제한다.
- 즉 하나의 DNS 이름을 갖고 애플리케이션 또한 하나의 DNS 이름으로 통신하며 마스터에 문제가 생길 때에도 스탠바이 데이터베이스에 자동으로 장애 조치가 수행된다.
- 이를 통해 가용성을 높일 수 있다.
- 마스터 데이터 베이스의 인스턴스 또는 스토리지에 장애가 발생할 때 스탠바이 데이터베이스가 새로운 마스터가 될 수 있도록 하는 것이다.
- StandBy 데이터 베이스는 스케일링에 이용되지 않는다. 단지 마스터 데이터베이스에 문제가 발생할 경우를 대비한 장애 조치일 뿐이다.
- 재해 복구를 대비해 읽기 전용 복제본을 다중 AZ로 설정할 수 있다.
RDS - From Sing-AZ to Multi-AZ
- 다운 타임 없이 단일 AZ에서 다중 AZ로 RDS 데이터베이스 전환이 가능하다.
- 내부적으로 main database의 RDS가 자동으로 DB snapshot을 생성한다.
- 이 스냅샷은 새로운 스탠바이 데이터베이스에 복원된다. 그 후엔 두 데이터베이스 간 동기화가 설정되므로 스탠바이 데이터베이스가 main RDS database 내용을 모두 수용하여 다중 AZ 상태가 설정된다.
RDS Custom
- RDS에서 기저 운영 체제나 사용자 지정 기능에 액세스할 수 없다.
- 하지만 RDS Custom에서는 가능하다.
- RDS Custom에서는 Oracle과 Microsoft SQL Server Database를 사용할 수 있다.
- 이를 통해 OS 및 데이터베이스 사용자 지정 기능에 액세스할 수 있다.
- RDS를 통해 AWS에서의 데이터베이스 자동화 설정, 운영 그리고 스케일링의 장점을 챙길 수 있다.
- 여기에 기저 데이터베이스와 운영체제에 액세스할 수 있게된다.
- 내부 설정 구성
- 패치 적용
- 네이티브 기능 활성화
- SSH 또는 SSM 세션 관리자를 사용해서 RDS 뒤에 있는 기저 EC2 인스턴스에 액세스할 수 있다.
- 여기에 기저 데이터베이스와 운영체제에 액세스할 수 있게된다.
- 사용자 지정 설정을 사용하려면 RDS가 수시로 자동화, 유지 관리 또는 스케일링 같은 작업을 수행하지 않도록 자동화를 꺼두는 것이 좋다.
Amazon Aurora
- AWS 고유의 기술이다.
- PostgresSQL, MySQL 와 호환되도록 만들었다.
- AWS cloud에 최적화 되어 있고, 기타 최적화를 통해 RDS의 MySQL보다 5배 높은 성능이고, PostgreSQL보다 3배 높은 성능이다.
- 공유 스토리지 볼륨은 10GB에서 128TB까지 자동으로 확장된다.
- 읽기 전용 복제본의 경우 15개의 복제본을 둘 수 있다.(MySQL에서는 5개만 가능)
- Aurora의 장애 조치는 즉각적이다. 다중 AZ나 MySQL RDS보다 훨씬 빠르다.
- 기본적으로 클라우드 네이티브이므로 가용성이 높다.
- 비용은 RDS에 비해 약 20%정도 높지만, 스케일링 측면에서 훨씬 더 효율적이기 때문에 오히려 비용 절감을 할 수 있다.
Aurora High Availability and Read Scaling
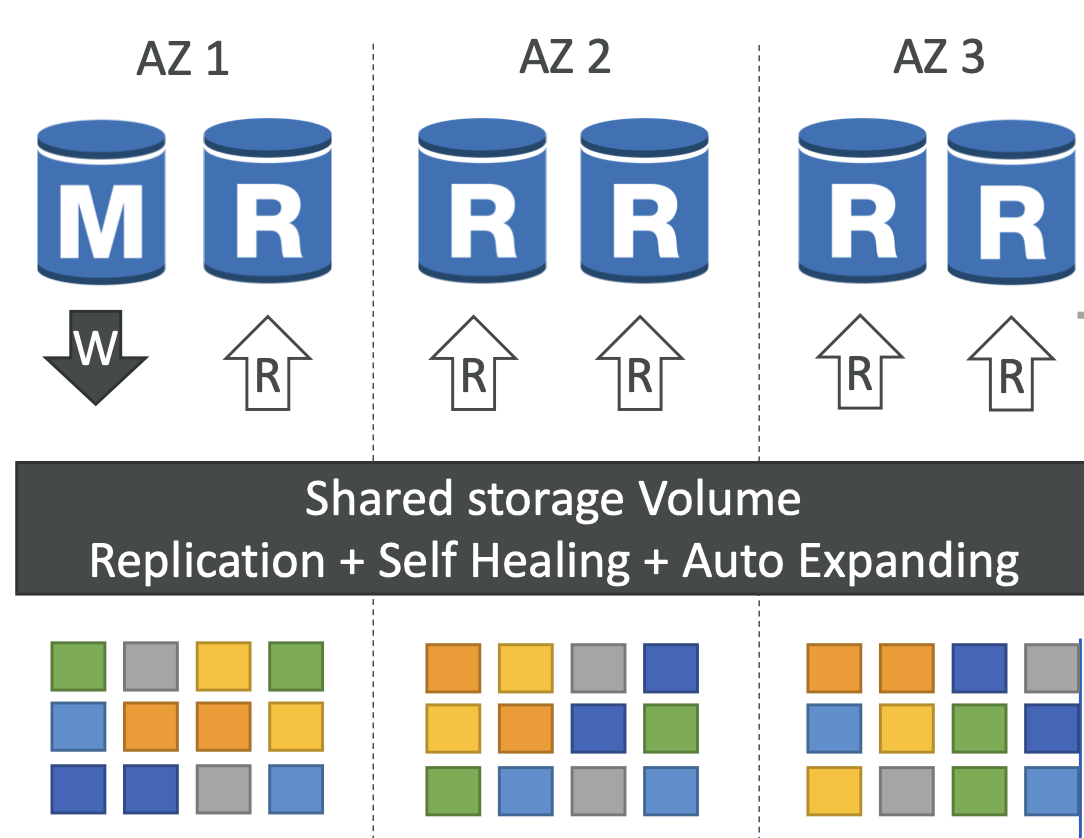
- 3개의 AZ에 걸쳐 무언가를 기록할 때마다 6개의 사본을 저장한다.
- 쓰기에는 6개 사본 중 4개만 있으면 된다.
- 읽기에는 6개 사본 중 3개만 있으면 된다.
- 자가 복구 과정이 존재한다.
- 일부 데이터가 손상되거나 문제가 있으면 백엔드에서 P2P 복제를 통한 자가 복구가 진행된다.
- 단일 볼륨에 의존하지 않고 수 백 개의 볼륨을 사용한다.(3개의 AZ에 스트라이프 형식으로 저장되어 리스크를 줄여준다)
- Master Aurora 인스턴스만 write 기능을 담당한다
- 장애 조치가 30초 이내에 동작하여 매우 빠르다.
- 마스터 외에 읽기 전용 복제본을 15개까지 둘 수 있다.
- 리전 간 복제를 지원한다.
- back track이라는 특정 시간대의 시점으로 돌아가는 서비스도 존재한다(snap shot의 개념이 아니다)
- 다른 리전에 추가할 수 있는 global aurora 기능도 존재한다.
Aurora DB Cluster
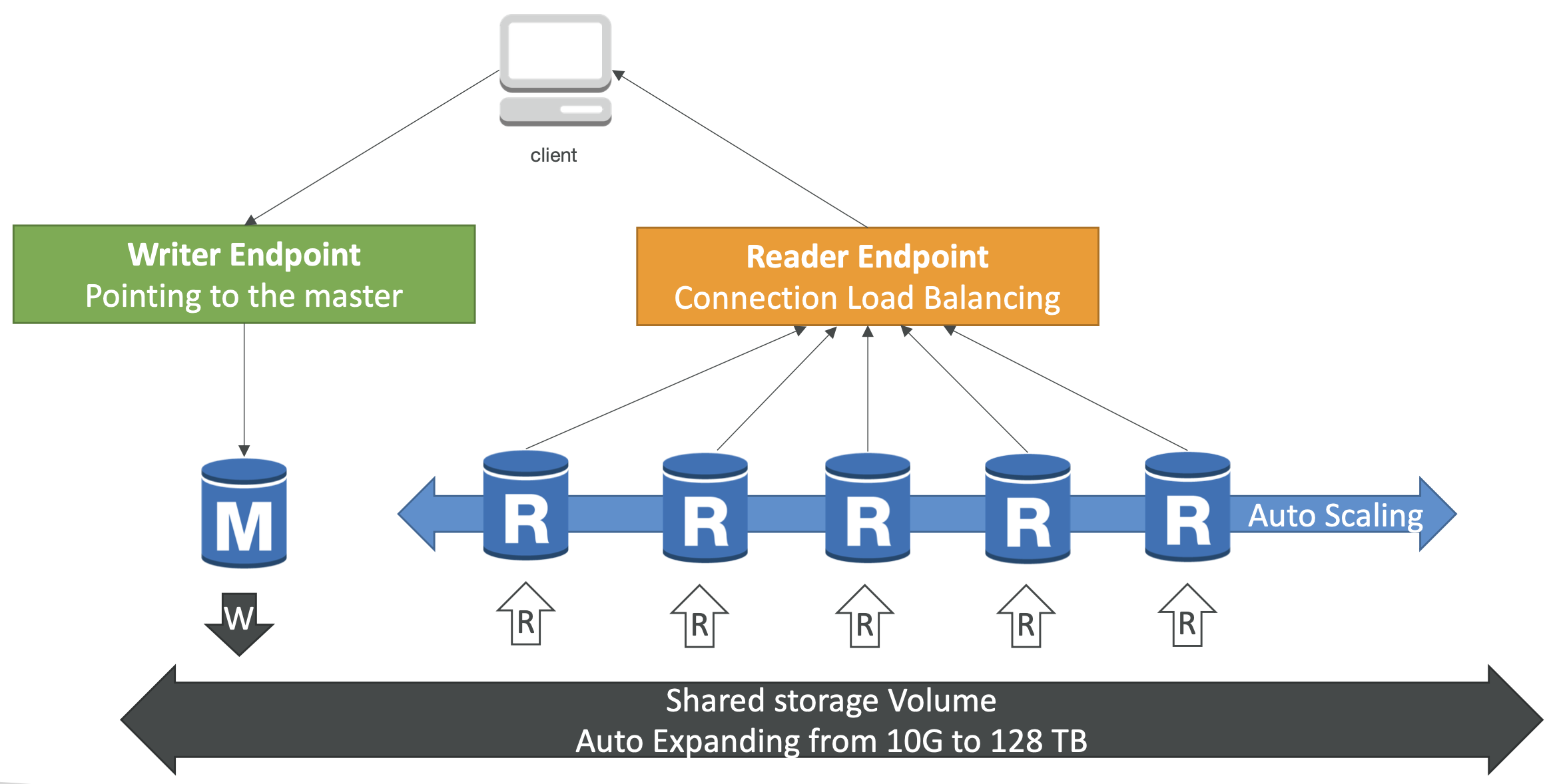
- writer 엔드포인트는 DNS 이름으로 항상 마스터를 가리킨다.
- 따라서 장애 조치 후에도 클라이언트는 writer 엔드포인트와 상호작용하게 되며 올바른 인스턴스로 자동 리다이렉트 된다.
- 오토 스케일링을 통해 읽기 전용 복제본이 적절하게 존재하게 한다.
- 자동 스케일링이 켜져 있는 경우 application 입장에서는 복제본이 어디에 있고, URL은 무엇인지 알기 어렵다. 이를 위한 기능으로 reader end point가 존재한다.
- reader 엔드 포인트는 writer 엔드 포인트와 동일하게 연결 로드 밸런싱에 도움을 준다.(모든 읽기 전용 복제본과 자동으로 연결된다.)
- 로드 밸런싱이 statement level이 아닌 connection 레벨에서 일어난다.
Aurora Replicas - Auto Scaling
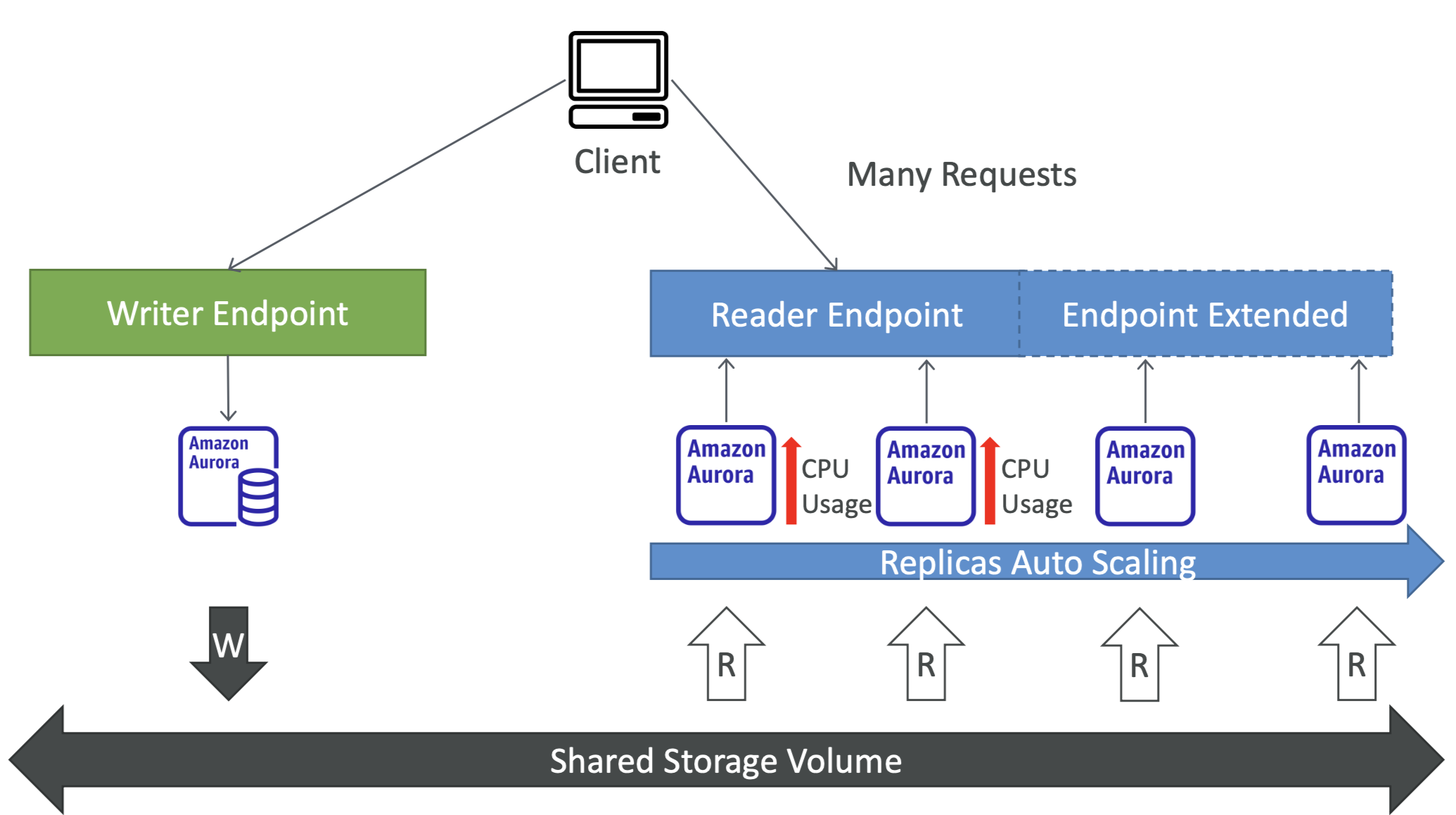
Aurora - Custom Endpoints
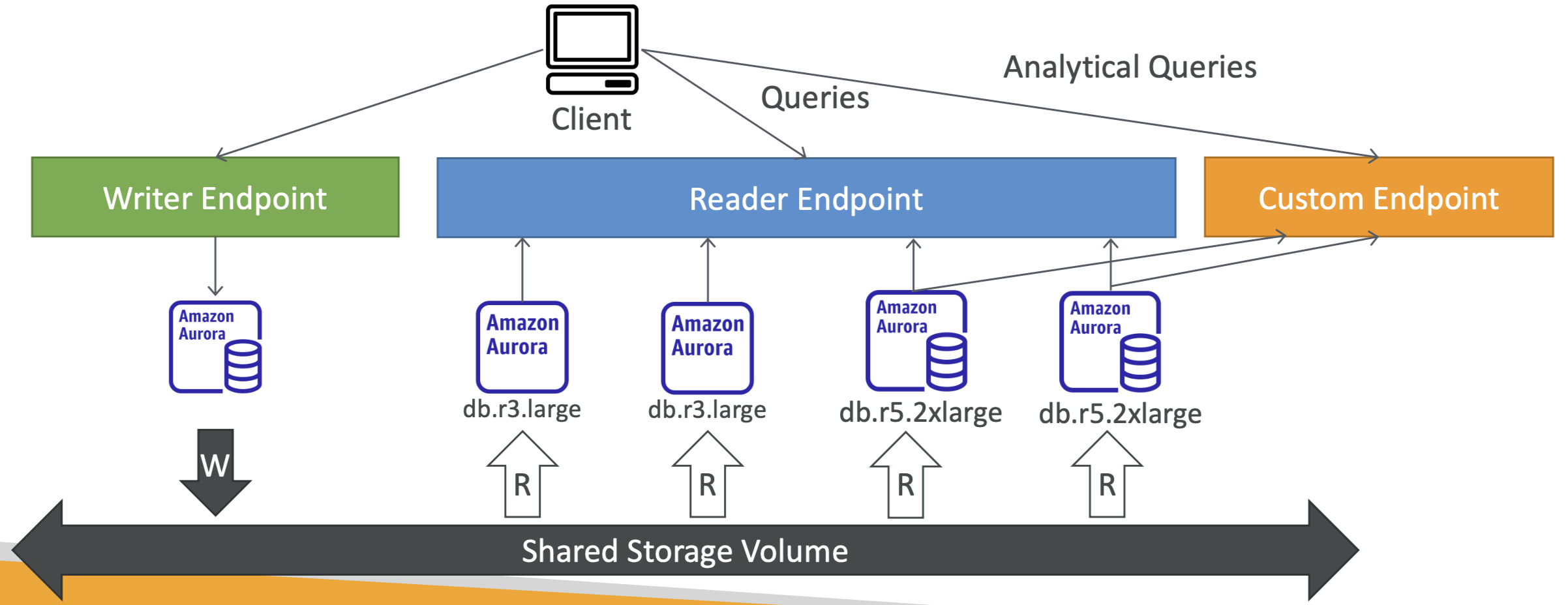
- 위와 같이 사용자 지정 엔드포인트를 지정하여 특정 application의 요청을 처리할 수도 있다.
Aurora Serverless
- 서버리스를 통해 자동화된 데이터베이스 instantiation과 실제 사용량에 따른 Auto Scaling을 제공한다.
- 이는 간헐적이고 예측 불가능한 업무량에 대응하는 것을 도와준다.
- 그러므로 capacity planning을 할 필요가 없게 된다.
- 활용하고 있는 Aurora 인스턴스 마다 초당 비용 지불을 하는 것이 훨씬 비용 효율적이다.
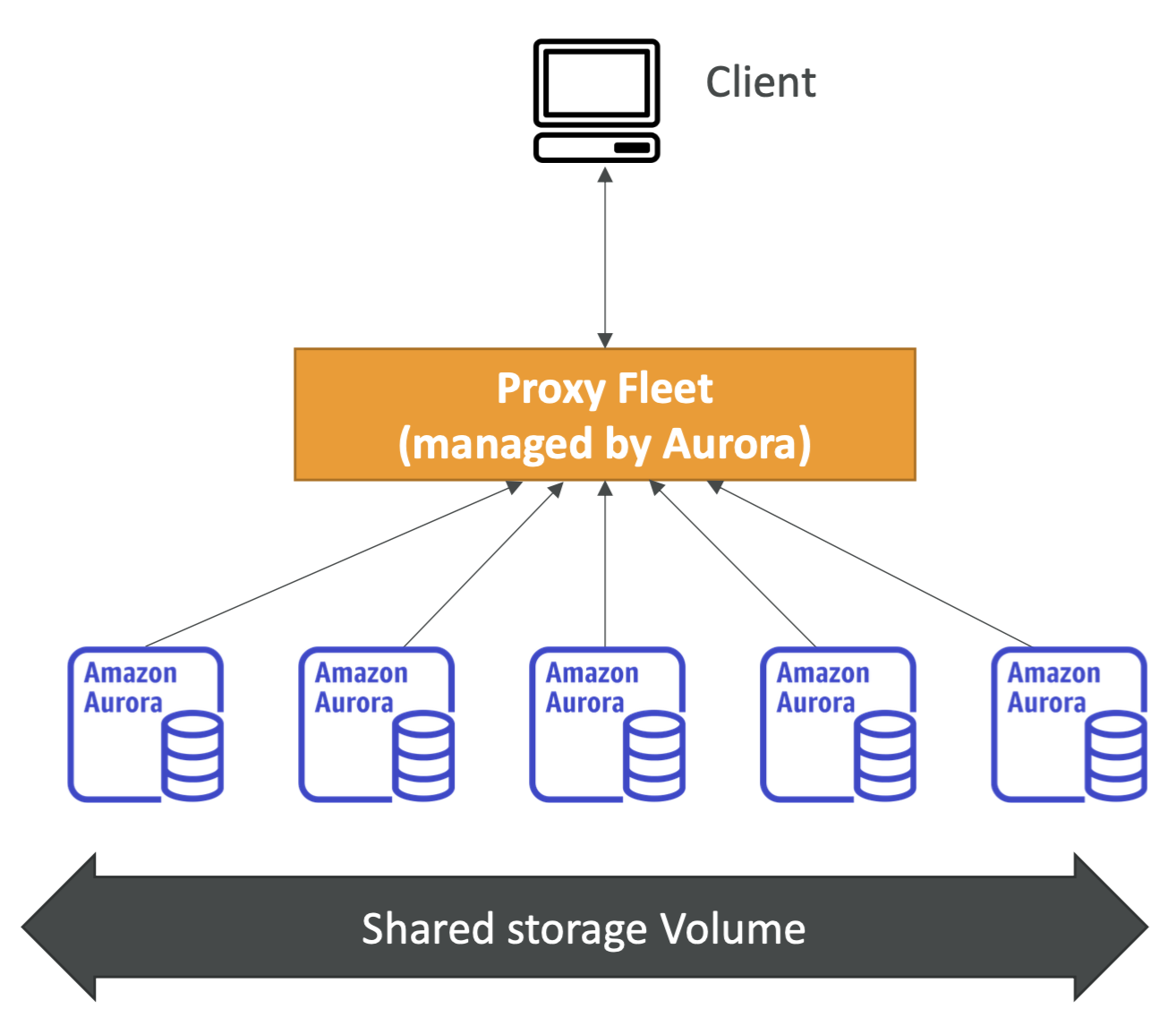
- 클라이언트는 Aurora가 관리하는 Proxy Fleet과의 연결을 통해 백엔드에 Aurora 인스턴스들이 생성된다. 이는 업무량에 기반한 서버리스 방식으로 동작한다.
- 이로 인해 미리 용량을 준비하지 않아도 된다.
Global Aurora
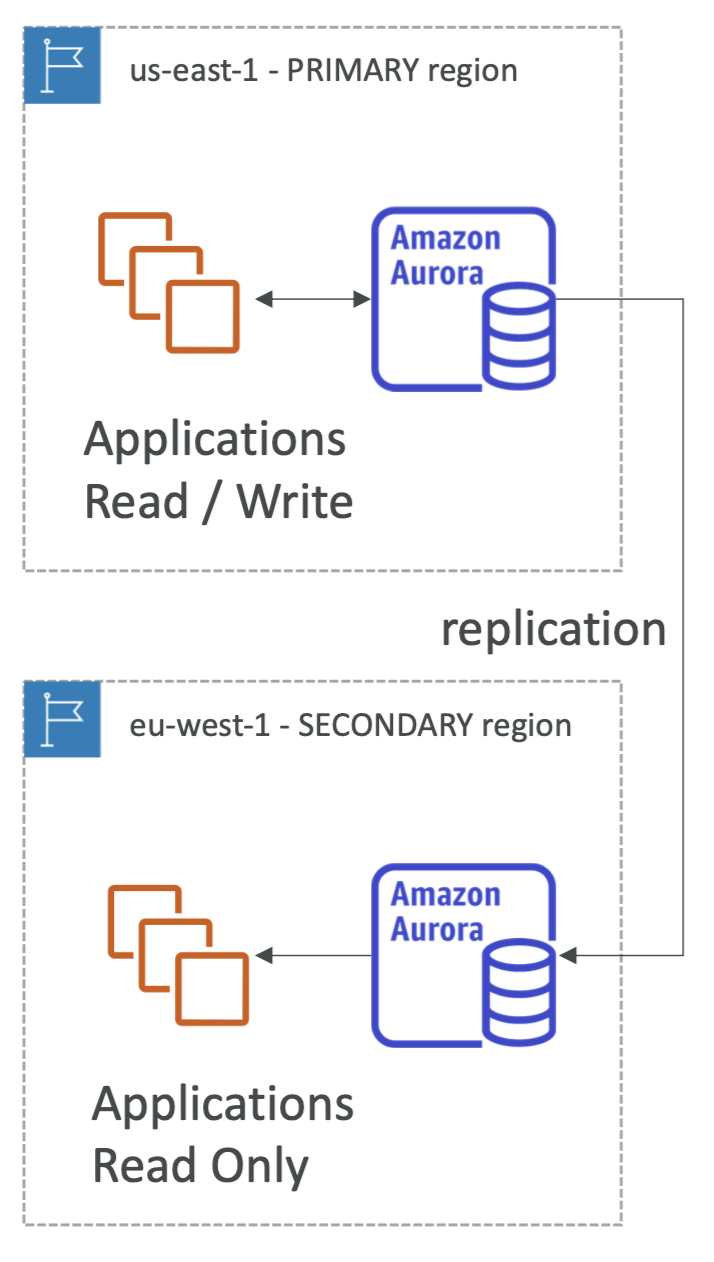
- Aurora 교차 리전 읽기 전용 복제본은 재해 복구를 지원하고, 실행하기 간단하다.
- 그럼에도 Aurora Global Database가 요즘 추천되는 방식이다.
- 이 경우 모든 읽기와 쓰기가 일어나는 하나의 기본 리전이 존재한다.
- 최대 5개의 보조 읽기 전용 리전을 만들 수 있다.(이는 응답 지연이 1초 이하이다.)
- 보조 리전 당 최대 16개의 읽기 전용 복제본을 사용할 수 있다.
- 한 리전에 데이터베이스 중단이 일어날 경우 재해 복구를 위해 다른 리전을 승격 시킨다.(1분 이내로 복구)
- 평균적으로 Aurora 글로벌 데이터 베이스에서 한 리전에서 다른 리전으로 데이터를 복제하는 데에는 (1초 이하의 시간이 걸린다)
Aurora Machine Learning
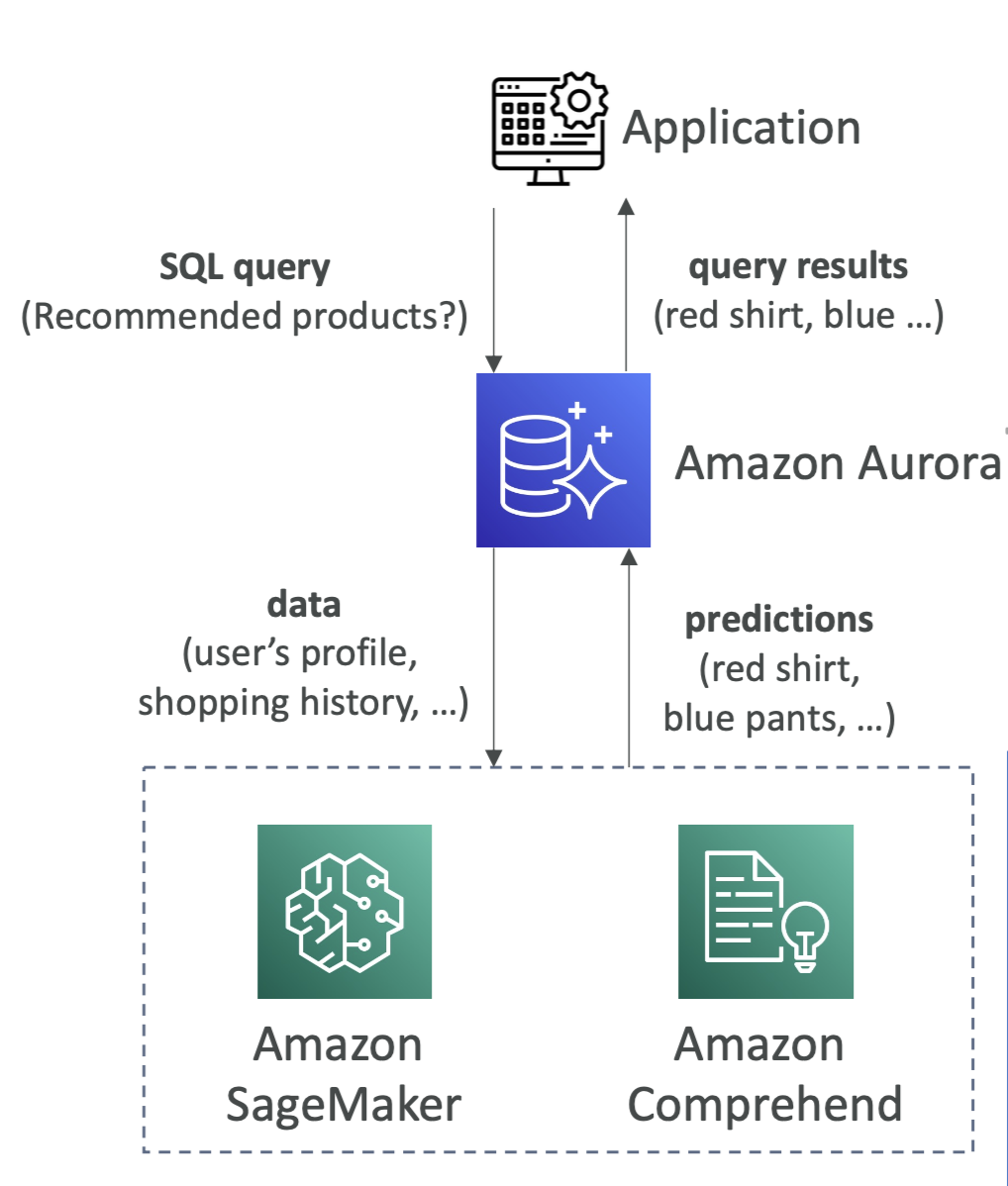
- Aurora는 AWS 안에 있는 기계 학습 서비스와 통합하기도 한다.
- SQL 인터페이스를 통해 응용프로그램에 기계 학습 기반의 예측을 추가할 수 있다. Aurora와 다른 AWS 기계 학습 서비스 간의 간단하고 최적화된, 안전한 통합이다.
- 지원되는 서비스
- AWS SageMaker(use with any ML model)
- AWS Comprehend(for sentiment analysis)
- Aurora 기계 학습을 사용하기 위해 기계 학습 경험이 필요하진 않고 사용 사례는 이상 행위 탐지, 광고 타겟팅, 감정 분석 상품 추천 등 모두 Aurora 안에 있다.
RDS Backups
- Automated backups
- 매일 자동으로 전체 백업을 수행한다.(데이터베이스 백업 기간 동안)
- 5분마다 트랜잭션 로그가 백업된다.
- 자동 백업 보존 기간은 1~35일 사이로 설정할 수 있다.
- 수동 데이터베이스 스냅샷
- 사용자가 수동으로 트리거한다
- 수동으로 한 백업을 원하는 기간 동안 유지할 수 있다(자동 백업은 만료기간이 있다)
- 한달 중 일정 기간 동안만 사용되는 데이터 베이스의 경우 사용 시간 이후 snapshot을 만든뒤 원본 데이터를 삭제하는 식으로 비용절감을 할 수 있다.
Aurora Backups
- RDS와 동일하게 Automated Backup이 존재한다.(하지만 비활성화 할 수 없다.)
- 시점 복구 기능이 있다. 즉, 해당 기간의 어느 시점으로든 복구할 수 있다.
- 수동 DB 스냅샷은 사용자가 수동으로 트리거 할 수 있으며, 원하는 기간 동안 유지할 수 있다.
RDB & Aurora Restore options
- 자동화된 백업이나 수동 스냅샷을 복원할 때마다 새 데이터베이스가 생성된다.
- 또는 S3에서 MySQL 데이터베이스를 복원할 수 있다.
- 온프레미스 데이터베이스의 백업을 생성한 다음 객체 스토리지인 Amazon S3에 배치하는 것이다.
- RDS에는 Amazon S3에서 백업 파일을 복원하는 옵션이 존재한다.
- S3에서 MySQL Aurora cluster로 복원하려는 경우, 온프레미스 데이터베이스를 다시 백업하면 된다. (Percona XtraBackup 이라는 소프트웨어를 사용하면 가능하다)
Aurora Database Cloning
- 기존 데이터베이스 클러스터에서 새로운 Aurora 데이터베이스 클러스터를 생성할 수 있다.
- 이 작업은 매우 빠르다.(스냅샷을 찍고 복원하는 것보다 더 빠르다)
- 복제는 copy-on-write 프로토콜을 사용하기 때문이다.
- 처음 데이터 베이스를 만들 때는 원래 데이터베이스 클러스터와 동일한 데이터 볼륨을 사용한다. 데이터를 복사하지 않기 때문에 빠르고 효율적이다.
- 프로덕션 Aurora 데이터베이스 또는 스테이징 Aurora 데이터베이스에 업데이트가 이루어지면 새로운 추가 스토리지가 할당되고, 데이터가 복사 및 분리된다.
- 데이터 베이스 복제는 빠르고 비용 효율적이며, 프로덕션 데이터베이스에 영향을 주지 않는다.
RDS & Aurora Security
- 저장된 데이터를 암호화 할 수 있다.
- KMS를 사용해 마스터와 모든 복제본의 암호화가 이루어진다.(이는 데이터베이스를 처음 실행할 때 정의된다.)
- 마스터 데이터베이스를 암호화하지 않았다면 읽기 전용 복제본을 암호화 할 수 없다.
- 또한 암호화 되어있지 않은 기존 데이터베이스를 암호화 하려면 암호화 되지 않은 데이터베이스의 스냅샷을 가지고 와서 암호화된 형태로 복원해야 된다.
- In-flight encryption(전송 중 데이터 암호화)는 RDS와 Aurora에 기본적으로 갖추고 있는 기능이다. 따라서 클라이언트는 AWS의 TLS 루트 인증서를 사용해야한다.
- IAM Authentication : IAM 역할을 사용해서 데이터베이스에 접속할 수 있다. 예를 들어 EC2 인스턴스에 IAM 역할이 있다면 이를 사용해 사용자 이름이나 패스워드 없이 직접 데이터베이스를 인증할 수 있다.
- Security Groups : 보안 그룹을 사용해서 데이터베이스에 대한 네트워크 액세스를 통제할 수 있다. 특정 포트, IP, 보안 그룹을 허용하거나 차단할 수 있다.
- RDS와 Aurora는 SSH 액세스가 없다. 관리형 서비스가 있기 때문이다. (RDS Custom은 예외)
- Audit Logs를 사용하여 실행된 쿼리 등의 로그를 볼 수 있다. 장기 보관하고 싶다면 CloudWatch Logs에 전송하여 볼 수 있다.
Amazon RDS Proxy
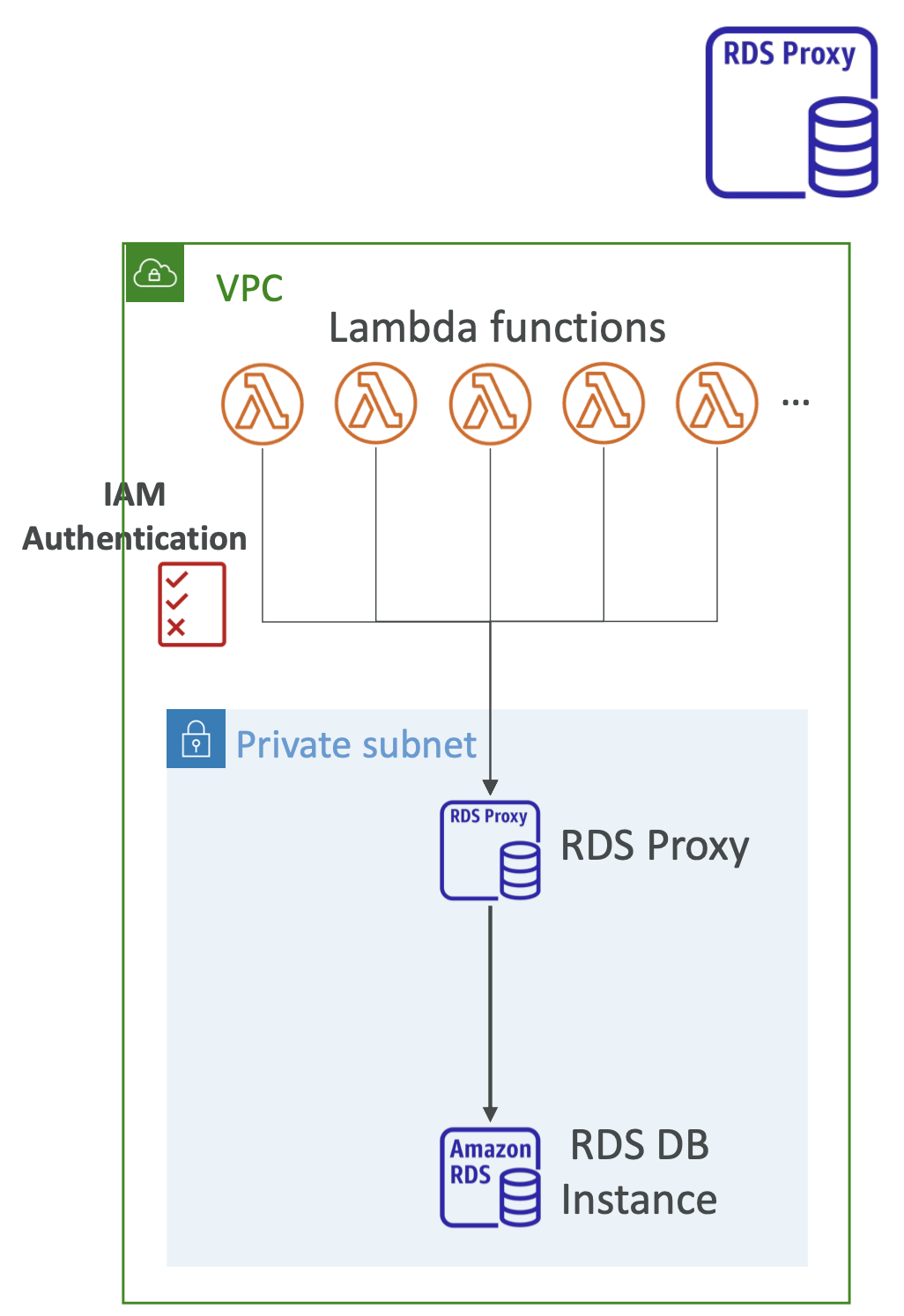
- 완전 관리형 RDS 데이터베이스 프록시를 배포할 수 있다.
- 애플리케이션이 데이터베이스 내에서 데이터베이스 연결 풀을 형성하고 공유할 수 있는 장점이 있다. (애플리케이션을 RDS DB 인스턴스에 일일이 연결하는 대신 프록시에 연결하면 RDS DB 인스턴스로 가는 연결이 줄어든다.)
- 이를 통해 CPU와 RAM 등 데이터베이스 리소스의 부담을 줄여 데이터베이스 효율성을 향상 시킬 수 있고, 데이터베이스에 개방된 연결과 시간초과를 최소화할 수 있기 때문이다.
- RDS 프록시는 완전한 Serverless로 오토 스케일링이 가능해 용량을 관리할 필요가 없고 가용성이 높다.(다중 AZ도 지원한다)
- RDS 프록시를 통해 장애 조치 시간을 66%까지 줄일 수 있다.
- 메인 RDS 데이터베이스 인스턴스에 애플리케이션을 모두 연결하고 장애 조치를 각자 처리하게 하는 대신 장애 조치와 무관한 RDS 프록시에 연결한다.
- RDS 프록시가 장애 조치가 발생한 RDS 데이터베이스 인스턴스를 처리하므로 장애 조치 시간이 개선된다.
- RDS 프록시는 MySQL, PostgreSQL, MariaDB RDS와 MySQL용, PostgreSQL용 Aurora를 지원한다.
- 애플리케이션의 코드를 변경하지 않아도 된다.
- 데이터베이스에 IAM 인증을 강제함으로써 IAM 인증을 통해서만 RDS 데이터베이스 인스턴스에 연결하도록 할 수 있다.(AWS Secrets Manager 서비스에 안전하게 저장된다)
- RDS 프록시는 퍼블릭 액세스가 절대로 불가능하다(VPC 내에서만 액세스할 수 있다.)
- 이후에 공부할 AWS Lambda를 활용해 사용하면 유용하다. 추후에 살펴볼 예정
Amazon ElastiCache
- RDS가 관계형 데이터베이스를 관리하는 것과 같은 방식이다.
- ElastiCache는 캐싱 기술인 Redis 또는 Memcache를 관리할 수 있도록 도와준다.
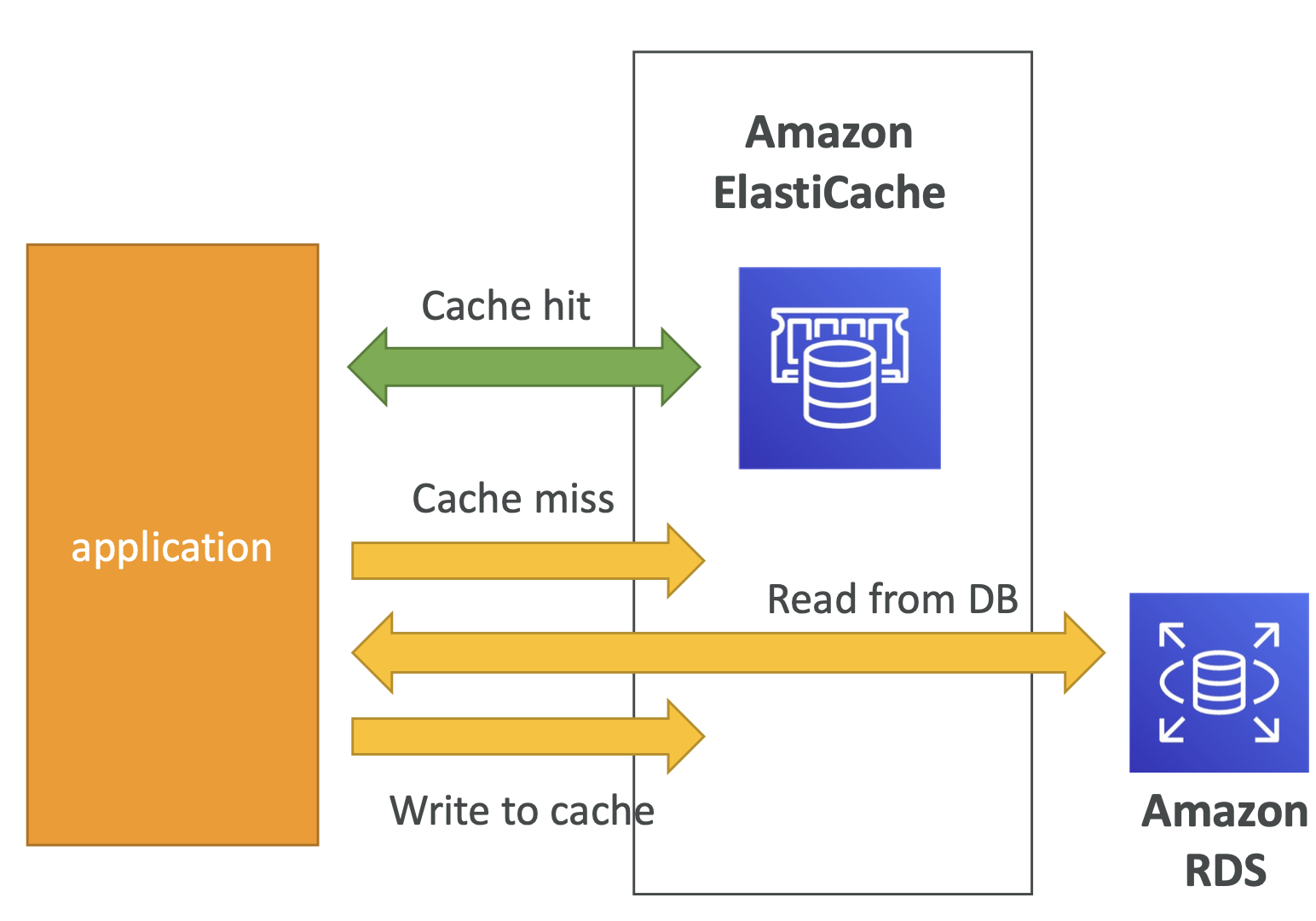
- Cache : 매우 높은 성능과 짧은 지연 시간을 가진 인메모리 데이터베이스이다.
- 캐시는 읽기 집약적인 워크로드에서 데이터베이스의 로드를 줄여준다.
- 일반적인 쿼리는 캐시에 저장되므로, 매번 데이터베이스를 쿼리하지 않아도 된다.
- 캐시만 사용하여 쿼리의 결과를 검색할 수 있다.
- 일반적인 쿼리는 캐시에 저장되므로, 매번 데이터베이스를 쿼리하지 않아도 된다.
- 애플리케이션의 상태를 비저장형으로 할 수 있게 도와준다. (애플리케이션의 상태를 Amazon ElastiCache에 저장해서)
- RDS와 동일한 이점이 있기 때문에, AWS는 데이터베이스의 운영 체제를 유지 관리할 수 있다.
- patching, Optimizations, setup, configuration, failure recovery, backup
- Amazon ElasticCache를 사용하는 경우 애플리케이션의 코드를 많이 바꿔야한다.
ElasticCache Solution Architecture - DB Cache 예시
ElastiCache Solution Architecture - User Session Store 예시
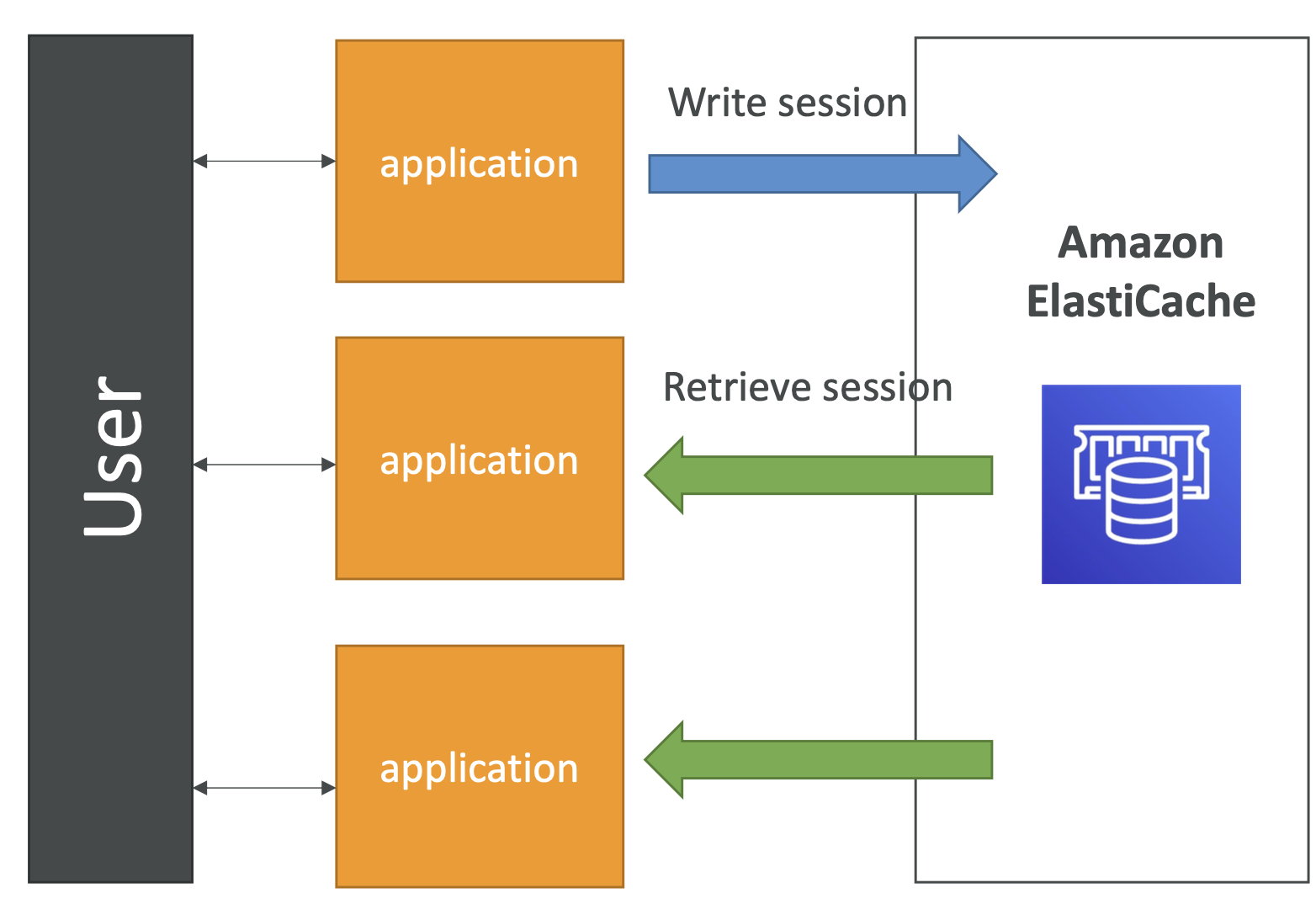
- 이 아키텍처는 애플리케이션을 상태 비저장으로 만들기 위해 사용자 세션을 저장하는 것이다.
- 즉, 사용자가 어떤 애플리케이션에 로그인하면, 애플리케이션이 세션 데이터를 Amazon ElastiCache에 쓴다.
- 사용자가 애플리케이션의 다른 인스턴스로 리다이렉션되면, 애플리케이션은 그 세션의 세션 캐시를 Amazon ElastiCache에서 직접 검색할 수 있으므로, 사용자는 여전히 로그인 상태이다. 다시 한번 더 로그인할 필요가 없다.
ElastiCache - Redis vs Memcached

- Redis
- 자동 장애 조치 기능이 있는 Mutli-AZ가 있고, 읽기 복제본이 있다.
- Read replicas to scale reads and have high availability
- AOF persistance를 이용한 데이터 내구성이 있다.(백업 및 복원 기능이 있다.)
- 즉, Redis는 데이터 내구성에 대한 것이다. 기능면에서는 캐시로서 세트 및 정렬된 세트를 지원한다.
- 복제되는 캐시이기 때문에 가용성과 내구성이 뛰어난 것이라고 생각하면 된다.
- Memcached
- 데이터 분할을 위해 멀티 노드를 사용한다(이를 sharding이라 한다)
- 고사용성이 없고 복제가 일어나지 않으며 영구 캐시가 아니다.
- 백업 및 복원도 없다.
- Multi-threaded architecture이다
- Memcached는 분산되어 있는 순수한 캐시이다. 데이터가 손실되어도 괜찮은 경우에 적합하고, 고가용성이 없으며 백업 및 복원 기능이 없다.
ElastiCache - Cache Security
- ElastiCache는 Redis에서만 IAM 인증을 지원하며, 나머지 경우에는 사용자 이름과 비밀번호를 사용하면 된다. ElastiCache에서 IAM 정책을 정의하면 AWS API 수준 보안에만 사용된다.
- Redis 클러스터를 만들때, Redis AUTH라는 Redis 내의 보안을 통해 비밀번호와 토큰을 설정할 수 있다. (보안 그룹 상에서 캐시에 추가 보안 수준을 제공하는 것이다.)
- SSL 전송중 암호화 또한 지원한다.
- Memcached
- SASL 기반 승인을 제공한다.
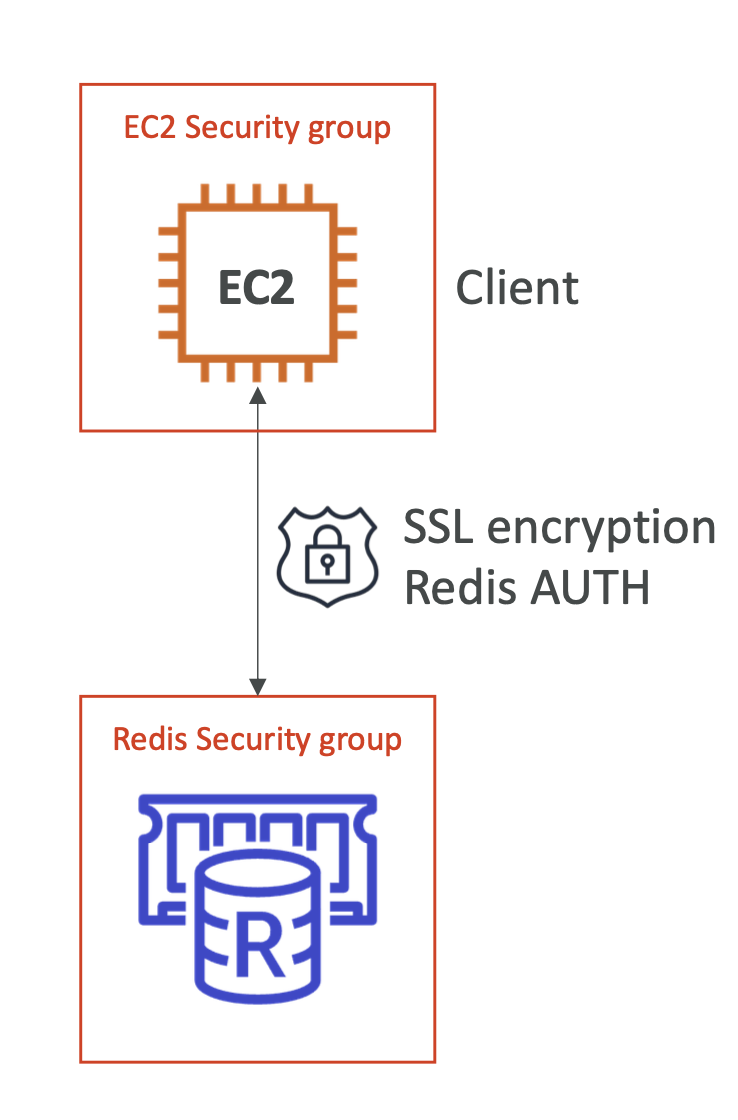
- 예를 들어 EC2 인스턴스와 클라이언트가 있는 경우 Redis AUTH를 사용한다.
- Redis 클러스터에 연결하여 Redis 보안 그룹에 의한 보호를 받을 수 있다.
- 또한 in-flight encryption을 사용하거나 Redis에서 IAM 인증을 활용할 수 있다.
Patterns for ElastiCache
- Lazy Loading : 모든 데이터가 캐시되고 데이터가 캐시에서 지체될 수 있다.
- Write Through는 데이터베이스에 데이터가 기록될 때 마다 캐시에 데이터를 추가하거나 업데이트 하는 것이다. 데이터가 지체되지 않는다.
- Session Store : 유지 시간 기능을 사용해 세선을 만료할 수 있다.
ElastiCache - Redis Use Case
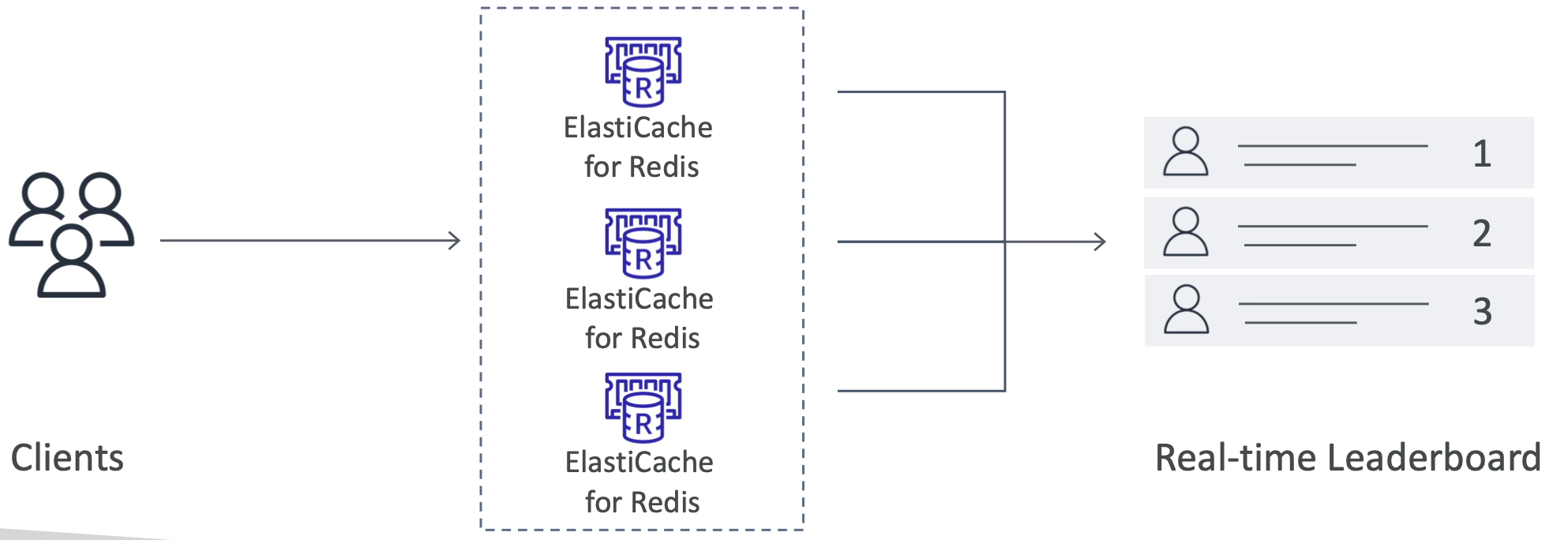
- Gaming LeaderBoards 만들기 예시이다
- 게임을 하는 매순간 순위의 변동을 반영해줘야 하는 요구사항이 필요한 애플리케이션이다
- Redis에는 정렬된 세트라는 것이 있다. 고유성과 요소 순서를 모두 보장한다.
- 요소가 추가될 때 마다, 실시간으로 순위를 매긴 다음 올바른 순서로 추가된다.
- Redis 클러스터가 있는 경우 실시간 리더보드를 만들 수 있다.
- 즉, 클라이언트가 Redis를 사용하여 Amazon elasticache와 대화할 때 이 실시간 리더보드에 액세스할 수 있으며, 애플리케이션 측에서 이 기능을 프로그래밍할 필요가 없다.
This post is licensed under CC BY 4.0 by the author.